Golang-GC笔记-Semantics
来源:https://www.ardanlabs.com/blog/2018/12/garbage-collection-in-go-part1-semantics.html
Garbage collectors responsibility
- tracking heap memory allocations
- freeing up allocations that are no longer needed
- keeping allocations that are still in-use
As of version 1.12, the Go programming language uses a non-generational concurrent tri-color mark and sweep collector.
非分代并发三色标记和扫描收集器
Collector Behavior
collection工作会经历三个阶段
- Mark Setup - STW(Stop The World)
- Marking - Concurrent
- Mark Termination - STW
Mark Setup - STW
collection开始时候第一个活动就是打开Write Barrier,目的是允许collector在收集期间保持堆上的数据完整性,因为collection和application goroutines会同时运行。
为了打开Write Barrier,必须停止运行的application goroutine,该动作通常会很快,10~30 microseconds。
示例:
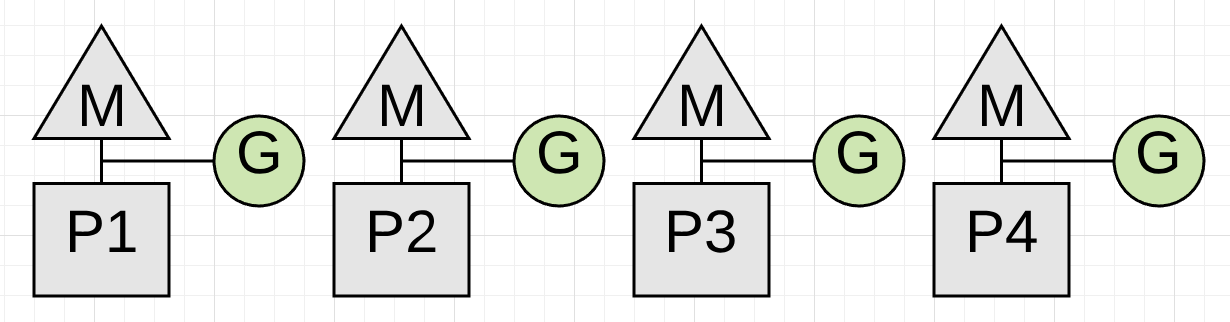
在collection之前必须停止正在运行的4个application goroutines,唯一停止的方法是让collector监视并等待每个goroutine进行一次function call,function call保证goroutine在safe point处停止。
假如其中一个goroutine没有进行function call,而其他的都进行了,会发生什么呢
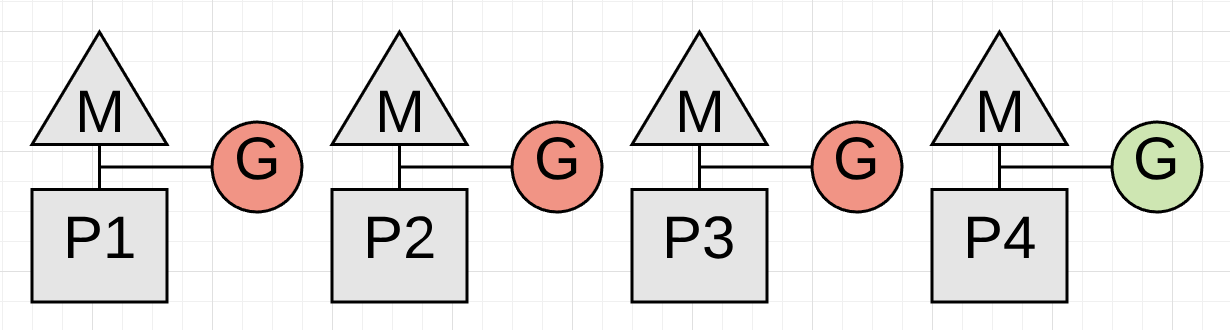
在P4上的goroutine停止之前,collection无法启动,因为处于数学计算中。
https://github.com/golang/go/issues/10958
Marking - Concurrent
25% CPU capacity
一旦打开了Write Barrier,collector就进入了Marking阶段,第一件事就是为自己申请25%可用CPU容量(CPU capacity)的占用。
collector使用goroutine完成collection工作,并且需要使用与application goroutine一样的P和M。
对于4线程的go程序(4 threaded Go program),一个完整的P将专门用于collection工作。
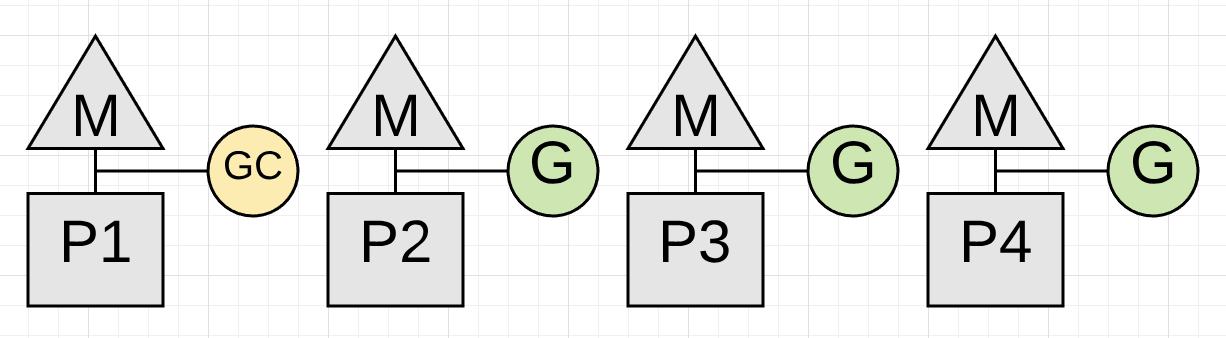
Marking
接着进入Marking阶段,标记堆内存(heap memory)中仍在使用的值。
首先会检查所有现有goroutine的stacks以找到指向heap memory的root pointers,然后collector必须从root pointers遍历heap memory graph。Marking进行时候,应用依旧可以在P2、P3、P4上继续进行。
如果P1上专门用于GC的goroutine在达到堆内存上限之前无法完成Markding工作,在这种情况下,新分配(new allocation)的速度必须放慢。collector确定需要放慢分配速度后,会招募application Goroutine来协助Marking工作,这称为MA(Mark Assist)。
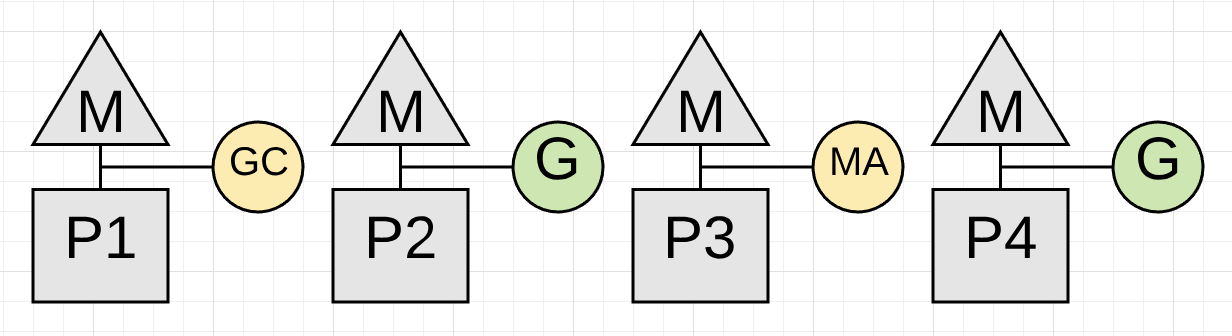
collector的一个目标是减少MA的需求。为了减少下一次collection工作需要的MA,某一次collection工作可能需要大量的MA,以便collector可以更早的开始下一轮GC(理解:时间间隔短应用分配的内存也少,需要的MA也少)。
标记的速度:4 CPU-milliseconds per MB of live heap
估计标记阶段要运行多久:take the live heap size in MB and divide by 0.25 the number of CPUs*
Mark Termination - STW
Marking完成后,下一个阶段是Mark Termination,将会关闭Write Barrier、执行各种清理任务、计算下一个收集目标。执行得同样迅速,60~90 microseconds。可以不通过STW实现以增加性能,但增加了复杂性,相比之下使用更好。
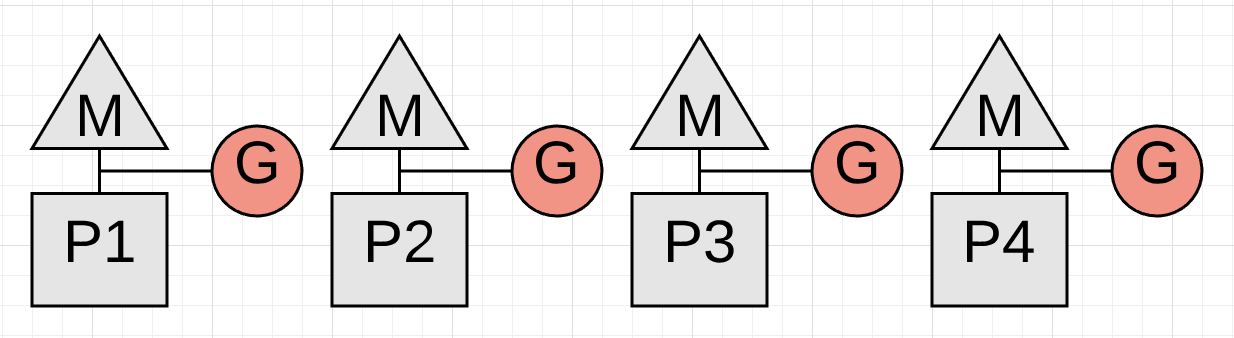
一旦collection工作完成,每个P都又可以被application goroutine使用。
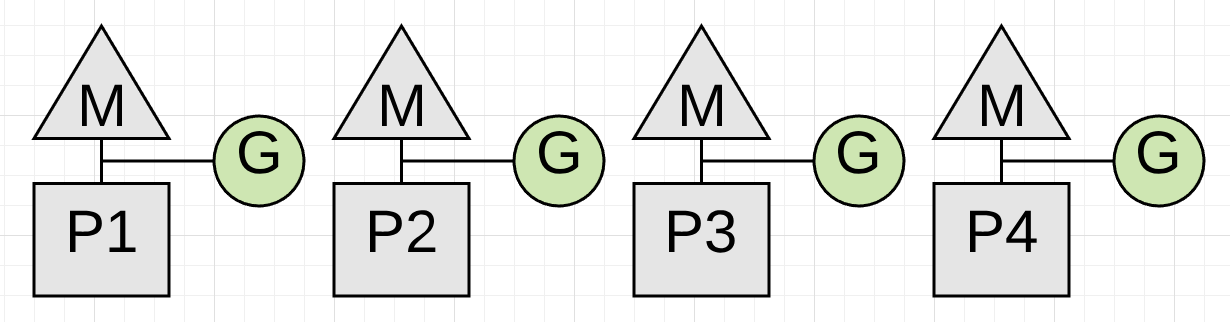
Sweeping - Concurrent
collection完成之后会发生另外一个动作:Sweeping,该动作会回收未标记的值的相关内存,当application goroutine尝试在堆内存中分配新值(allocate new values)的时候会触发该动作,产生的时间开销附加在堆内存分配产生的开销中。
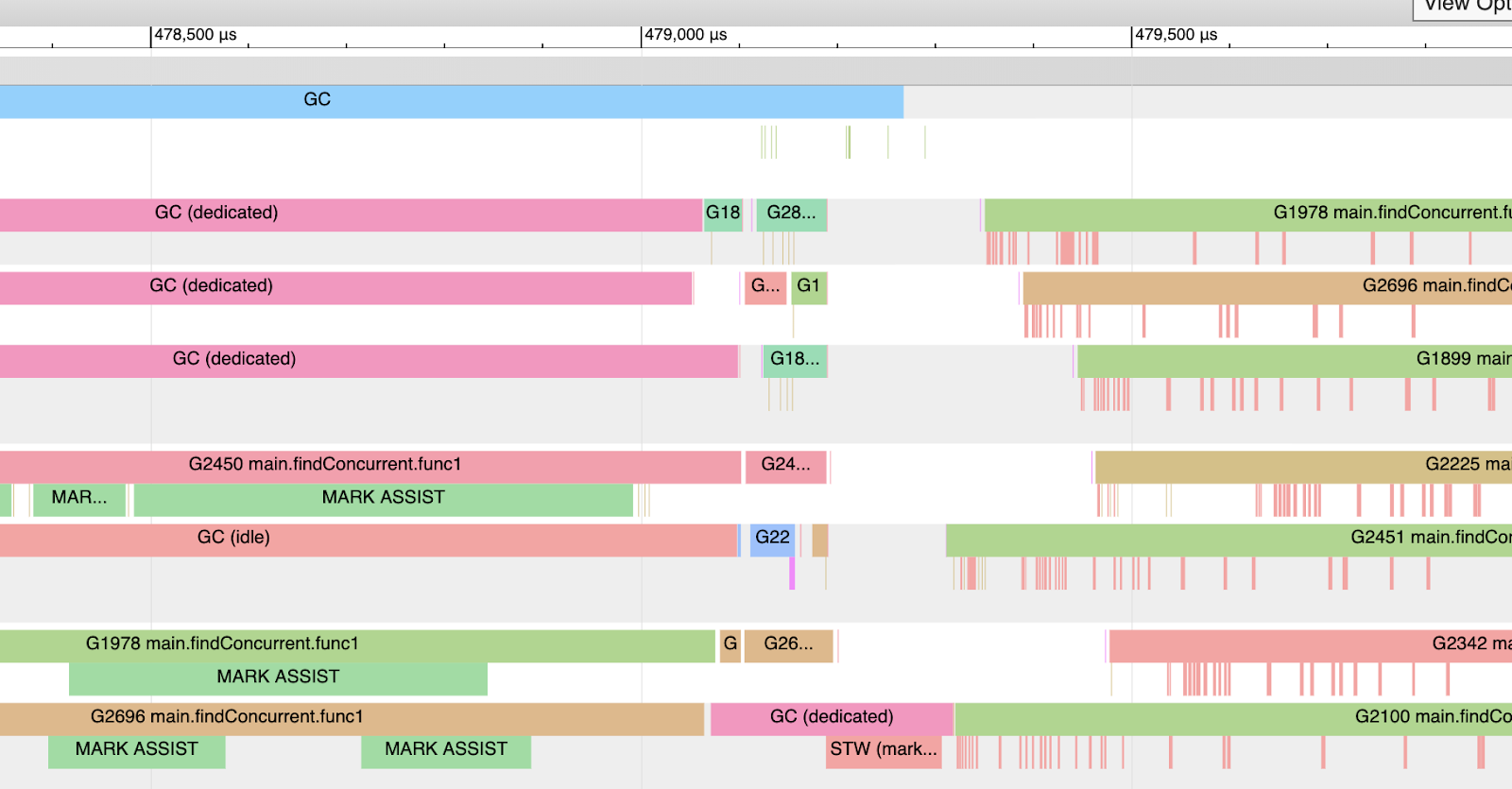
12个hardware threads可用于执行goroutine
在collection期间(左上角蓝色GC部分),十二个P中的三个专用于 GC。goroutine2450、1978、2696在这段时间内执行Mark Assit工作。collection工作完成后,只有一个P专门用于GC并执行Mark Termination工作。收集完成后,所有的P又可以被application goroutine使用(除了玫瑰色的细细线条外)。
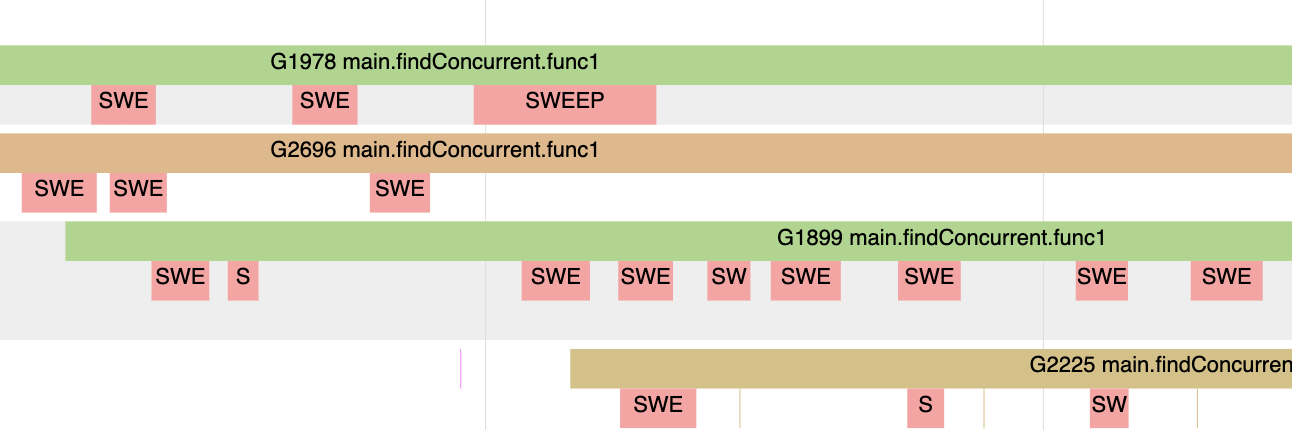
玫瑰色表示gouroutine执行sweeping工作而不是application工作,发生于goroutine尝试在堆内存中分配新值的时刻。
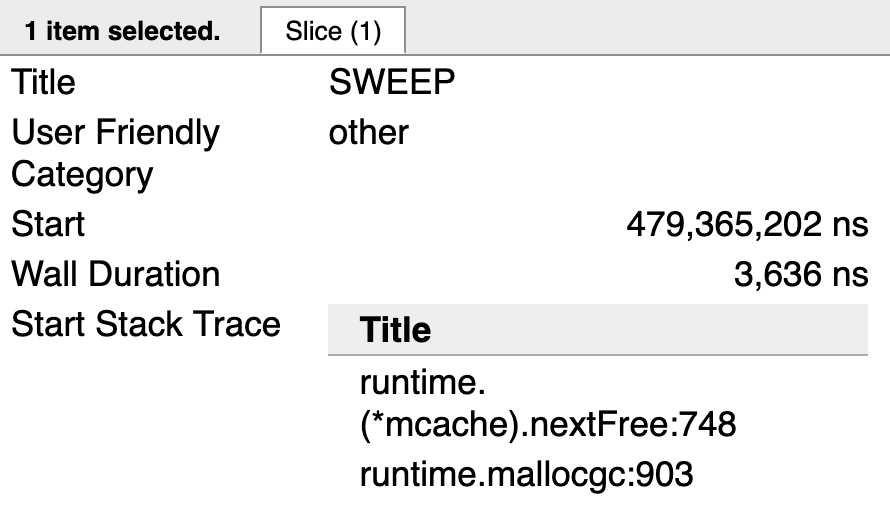
上图是执行了sweep工作goroutine的stack trace
runtime.mallocgc代表堆内存中分配新值,runtime.(*mcache).nextFree代表sweep动作。
GC Percentage
runtime中有个配置项目是GC Percentage,决定下一个collection动作何时发生。

上一次collection动作完成后显示正在使用(收集阶段的任务就是标记正在使用的内存)的堆内存为2MB(上图中的内存不一定是连续分配的,仅为了好理解),由于GC Percentage设置为了100(默认值),那么下一次collection动作会发生于堆内存新分配达到2MB时或者在这之前。
GC Trace
1 | GODEBUG=gctrace=1 ./app |
每次发生collection动作时候,runtime都会将GC trace information写入到stderr
GC1405
1 | gc 1405 @6.068s 11%: 0.058+1.2+0.083 ms clock, 0.70+2.5/1.5/0+0.99 ms cpu, 7->11->6 MB, 10 MB goal, 12 P |
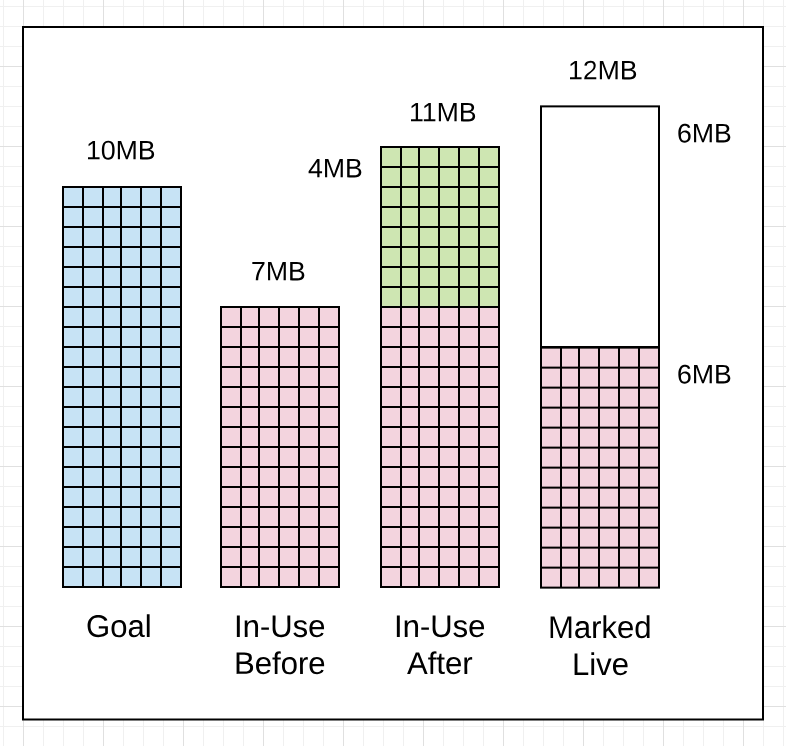
在Marking动作之前,正在使用的堆内存量为7MB,Marking完成后,使用中的堆内存达到11MB,意味着在collection期间发生了额外的4MB分配。Marking完成后,标记为活动中的堆内存量为6MB,这意味着应用程序在下一次collection开始之前可以将使用中的堆内存量增加到12MB(理想情况)。
global是根据使用中的堆内存量(before marking)、标记为活动中的堆内存量(after marking)、以及collection运行时发生的额外分配计算而来的。
GC1406
gc1406发生在gc1405 2ms之后
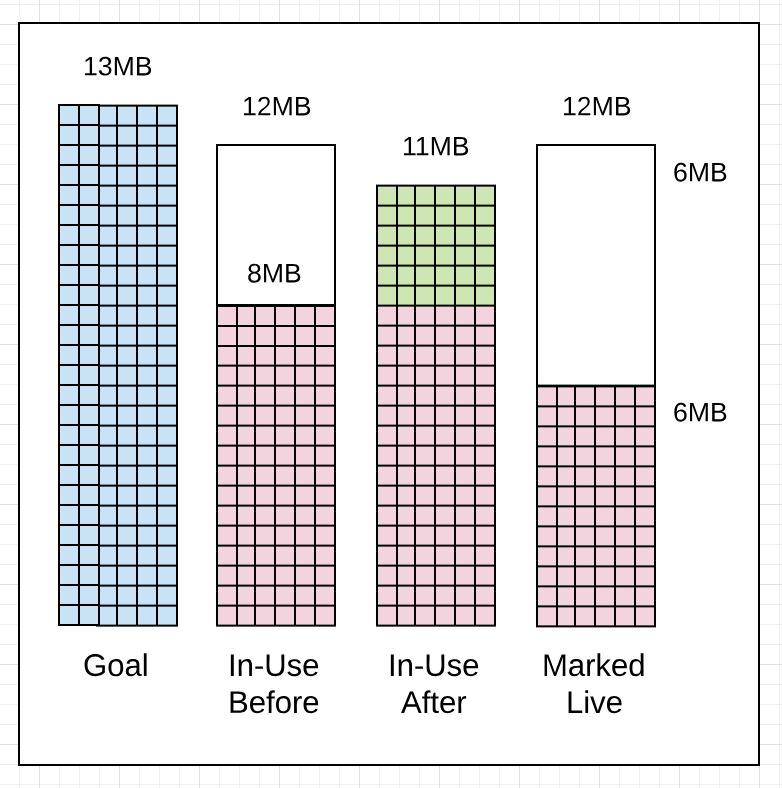
gc1405完成之后根据GC Percentage推测下一次触发时间为堆内存使用量达到12MB,但是这个是理想情况,如果collector决定最好早点开始collection动作那么则会早点开始,因为应用程序分配了大量内存,而collector希望减少收集期间Mark Assist使用量,所以当使用量达到8M的时候就开始了下一轮。
Pacing
collector有一个pacing算法用于确定何时开始collection工作。该算法依赖于feedback loop,collector用它来收集有关正在运行的应用程序和应用程序给堆施加的压力的信息,压力可以理解为给定时间内分配堆内存的速度,正是这种压力决定了collector的工作频率。
在collector开始collection工作之前,它会计算完成collection工作所需的时间。一旦collection工作运行,就会对在正在运行的应用程序上产生延迟,从而减慢应用程序的速度。
一个误解是认为降低collector的工作频率是提高性能的一种方式,比如将GC Percentage的值调大,这样可能就会导致collection频率降低?实际上这对于提高性能没有直接关系。
实际上与提高性能有关系的是每次collection完成之间(两个collectopn的间隔)应用程序执行的任务数量,可以通过减少堆内存的使用来影响到它以提高吞吐量。
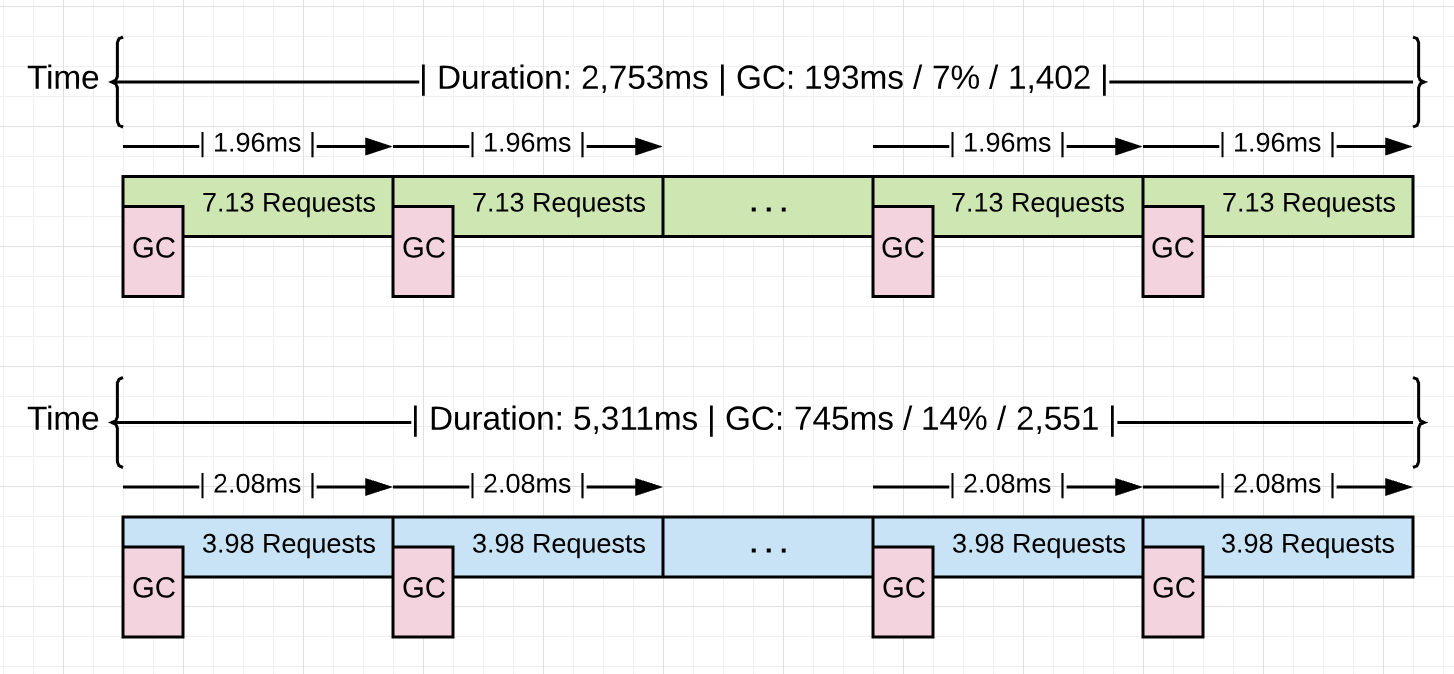
蓝色版本没有任何优化,绿色版本则是发现并去掉了4.48GB无关的内存分配(non-productive memory allocations)后的结果。
两个版本的collection平均频率相差不大(2.08ms vs 1.96ms),根本变化是每个collection之间完成的工作量,从每个间隔平均处理3.98个请求到7.13个请求。collection的频率并没有随着内存分配减少而减少,而是保存不变。
总的来说,尝试减少collection工作频率的措施并不是提高性能的方式,而减少collector运行需要的时间才是重要的,因为这个会减少因为延迟带来的成本。
当压力降低时候,collector造成的延迟将会减少,而这种GC延迟又是减慢应用程序的主要原因,所以减少堆内存的压力是正确的方法。
collector造成的影响有:
- Marking - Concurrent阶段会占用25%CPU性能
- Mark Assist
- STW(一般情况下花费时间少于100 microsecond)
可以减少延迟的措施有:
- 保持最少的使用堆内存
- 最大限度缩短每次collection、STW、Mark Assist持续的时间