
MIT6.824-LEC11-Cache-Consistency-Frangipani
为什么要阅读这篇论文
- cache coherence
- distributed transactions
- distributed crash recovery
- 三者的相互作用
整体的设计
- a network file system,与现有的应用程序共同工作,类似普通的unix程序。

可以将petal想象成一个磁盘,通过网络将数据共享给Frangipani,看起来就像从普通磁盘上读取数据
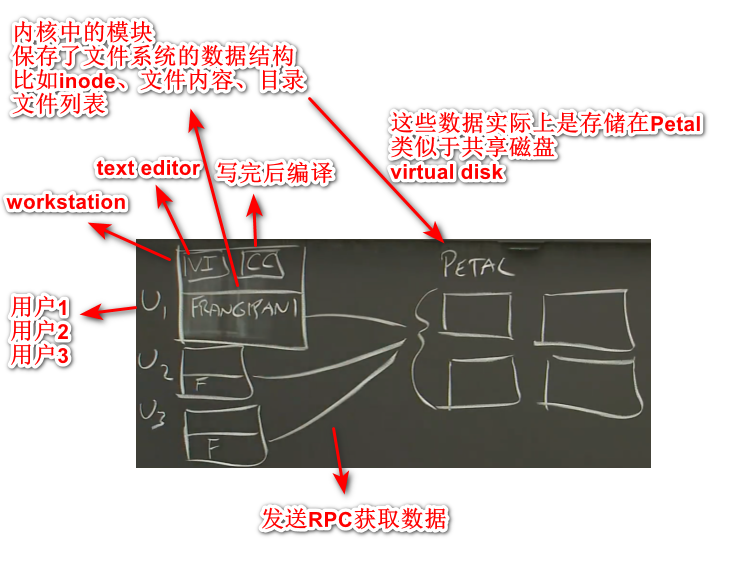
预期用途
- 一个文件系统,能保存自己的home目录以及共享的项目文件,在任何的workstation(可以理解是个人PC)能拿到自己的home目录以及所需要的所有文件。
- 没有涉及到安全问题,彼此电脑之间互相信任,适用于小群体
Frangipani的设计
- 强一致性
- caching in each workstation — write-back
- 所有对文件的更新最初只是在workstation cache中完成—速度快
- 包括创建文件、目录、重命名等
- 比如ws1(workstation user 1)想要创建并读写
/grades:Frangipani会从Petal读取/infomation的信息并保存到cache,然后添加/grades到cache,但是并不会立马将修改同步到Petal,因为ws1也许会继续修改/grades
- 所以Frangipani程序应该安装在workstation,而且petal不会知道workstation上面的文件以及目录信息,所有的逻辑处理复杂性都放在了Frangipani中
- 这是一种中心化方案(decentralized scheme)
- 添加更多workstation能添加更多CPU算力,有一定的扩展性,但是存储系统则会增加存储的负载,可能需要更多存储服务器。
挑战
- 主要来自caching、decentralized
- cache coherence:ws1创建
/A,ws2希望能看到/A(本地cache不会立即同步到Petal) - atomic multi-step operations:两个不同的workstation对同一个目录修改,比如ws1创建
/A,ws2创建/B,最终/应该有两个目录,不应该出现覆盖的情况(因为中间会有很多更新的步骤),或者是同时创建两个相同的文件。 - crash recovery:当一个workstation crash,不应该影响到其他用户,即使浏览crashed workstation目录下的文件,也应该看到正确的内容(没有损坏的,不一定要最新)
- Petal里面内置了一套完全独立的容错系统(很像之前讨论的Chain Replication),不在讨论的范围内。
cache coherence
- 目标是linearizability和caching,即同时兼备性能和一致性
- 许多系统使用了cache coherence protocols:多核处理器、file servers、distributed shared memory,但是Frangipani使用的不是这种,而是使用锁实现。
Frangipani’s coherence protocol
- lock server (LS), with one lock per file/directory,简化版,实际上Frangipani的锁更复杂,允许一个writer或者多个reader对文件操作
1
2
3
4file owner
-----------
x WS1
y WS1 - workstation (WS) Frangipani cache:每个workstation会去跟踪它持有的锁锁的种类:
1
2
3
4file/dir lock content(文件或者目录的实际内容)
-----------------------
x busy ...
y idle ...
- busy:正在使用数据
- idle:持有锁,但是现在不使用cached data(结束系统调用后由busy变成idle,比如创建文件、重命名、写入读取)
- workstation使用锁的规则,保证缓存一致性
- 只有持有该文件锁的时候,才能对这个文件的数据缓存
- 先获得锁,然后从Petal中读取数据,并保存到缓存
- 先将修改后的数据写回到Petal,再释放锁(会有定时将缓存写入到磁盘的机制,避免一直没有释放锁后又crash丢失数据)
- coherence protocol messages
- request (WS -> LS)
- grant (LS -> WS)
- revoke (LS -> WS):请求ws释放idle锁,一般情况下workstation创建了文件立即释放掉,而是由busy变成idle,因为绝大部分情况下,创建了文件还会对其操作。当ws收到revoke且能释放的时候(也就是ws此时没有对文件进行操作),如果缓存数据修改过,则需要按照第3条规则写回到Petal。
- release (WS -> LS)
示例:WS1更改文件z,然后WS2读取z
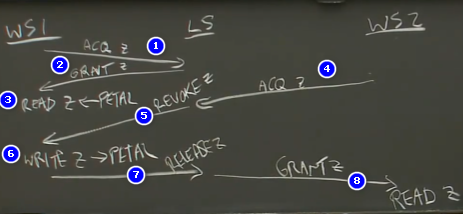
- WS1向LS请求文件z的锁
- WS1拿到锁
- 从Petal读取文件z的内容,保存到cache
- WS2向LS请求文件z的锁
- WS1持有这把锁,向WS1发送revoke请求
- 如果z被修改过,需要将更新后的z的内容写回到Petal
- WS1发送release给Petal,释放锁
- WS2拿到锁
- 锁和使用锁的规则保证最后一次的修改能被别人看到
- 优化点:
- 增加idle锁,避免频繁向LS请求
- 增加shared read lock、exclusive-write lock,共享读锁,当要写入时候回收读锁,写锁独占。
atomic multi-step operations
Frangipani实现了transactional file-system operations(创建文件、删除文件、重命名等),以保证原子性
- 获取该操作所需的所有锁
- 在持有所有锁的情况下执行操作,并将修改后的数据写到Petal
- 完成后释放锁
Frangipani的锁有两种作用:
- cache coherence:同步最新的写入
- transactional file-system:避免没有完成的操作让别的ws看到
crash recovery
- ws持有锁的时候崩溃(可能已经写入部分修改的数据到Petal)
- 此时不能直接释放对应的锁,因为操作还没有完成,释放后别的ws可能看到损坏的或者杂乱的数据,但是不释放锁别的ws就得一直等待锁。
write-ahead logging
Frangipani使用write-ahead logging实现crash recovery
- 将cache中的信息写入到Petal的之前,先在Petal写入这组完整操作的log(日志是ws一段段根据offset发送给Petal)
- 只有这组操作的log已经安全落地到Petal,ws才发送写操作给Petal
- 当已经写入部分到Petal的ws crash后,剩余的写入操作可以根据Petal的log完成
有两处与传统的logging方法不一样
- 当已经写入部分到Petal的ws crash后,剩余的写入操作可以根据Petal的log完成
- 在大部分事务系统中,只有一个地方存放log,并且所有的事务日志都存放于此,所以一次crash或者多个操作都可以影响到这段数据。而Frangipani则是每个ws都有单独的log,避免了记录log的瓶颈,但是某个文件的更新日志可能分散存到不同的位置。
- 在大部分事务系统中,事务log存放位置和执行事务的那台机器是在一起的,基本是存在本地磁盘,但是Frangipani的log存放在共享的Petal中,而不是ws本地磁盘,这样ws2可以读取crash ws1的log并恢复。
log中的内容
- 使用带有编号的block存储每个ws的日志
- 每个ws以环形队列的方式使用Petal上为它分配的空间,当空间用完的时候,ws可以从头写入,以此复用空间,但是在复用之前需要确保日志已经不需要(该日志的操作被Petal执行过了)
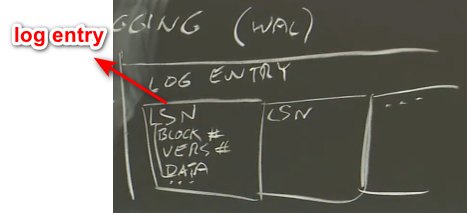
- log entry中的内容:
- LSN(log sequence number):递增的log entry number,如果ws崩溃了,Frangipani会去扫描它的日志,直到LSN不在递增为止。
- 描述数据更新的数组,每个元素都有:Petal上的block号、version number和需要写入的内容
- log中只有文件系统中的目录、inode、allocation bitmap的元数据修改信息,没有文件中实际的内容的信息,只是包含了crash后恢复文件系统结构的足够信息。比如在目录d下创建了文件f,增加一个log entry,里面有两条关于修改的描述:如何初始化f的inode、该文件在目录d下的新名字。
- 最初log entry只在ws的内存中,避免频繁写入Petal。
revoke
收到ls的revoke消息的时候,需要释放锁
- 将某些部分日志写到Petal的内存中,得确保日志是完整的
- 将已经修改的cache数据发送给Petal写入(这组数据修改操作的日志第一步已经发送了)
- 发送release消息释放锁
ws1在持有锁的时候崩溃
- ws2请求ws1持有的锁
- ls向ws发送revoke请求,没有得到响应,Frangipani的lock使用了lease的设定,当超过了lease time,就会判定ws肯定崩溃了。
- ls告诉ws2根据Petal的日志恢复ws1(根据ws1的log写入到Petal,有一些checksum机制确保每个log entry都是完整的,避免执行没有写完整的log entry)
- 完成后告诉ls才能释放锁
- ws1可能没有将log写回到Petal就崩溃了,或者是在写的过程中崩溃了,那么可能会丢掉ws1做的一些操作,但是其他的ws不会收到影响。
- 另外一种情况是ws1将日志发送给Petal完成后或者只发送了一点缓存数据后就崩溃了,但是进行恢复工作的ws2并不知道ws1什么时候崩溃了,ws2需要重新执行log(可能会在相同的地方写入相同的内容)
版本号机制保证不会执行旧的日志
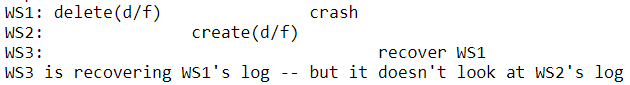
- ws1删除完d/f,ws2接着创建d/f,然后ws1崩溃了,接着ws3要恢复ws1
- 对于Petal中所保存的数据(元数据、目录、数据块等)来说都有一个版本号,当修改元数据并保存更新后的数据的时候会对版本+1。所以如果一个ws没有故障,并且成功的将数据写回到了Petal,这样元数据的版本号会大于等于Log条目中的版本号。如果有其他的工作站之后修改了同一份元数据,版本号会更高。
- 如果Petal中的版本号大于等于log entry中的版本号,ws3就忽略该日志,所以上述场景ws3不会执行ws1删除的日志,其他的日志同理,选择性的恢复。
- 当ws3进行恢复工作的时候,ws2可能持有着该目录所对应的锁,此时ws3查看ws1的log时候需要锁,这个应该怎么解决?
- 一种不可行的方法是让ws3先获取所有的锁,再执行恢复动作。当发生系统级的供电故障后,所有持有锁的信息都丢失了,就没有了之前锁提供的两种保障,此时就不能随便恢复。
- 实际上,ws3可以在不关心锁的情况下对Petal进行数据读写。ws1要么释放了锁,要么没有。如果没有,那么没有其他人可以读写该目录,ws3可以放心地写。如果释放了锁,根据版本号比对就知道不用恢复该数据了。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 GreenHatHGのBlog!
相关推荐
2025-12-18
MIT6.824-MapReduce
背景有时候我们需要从一批数据中得到一些结果,比如从最频繁查询的结果集,每个单词出现的次数。随着输入的数据越来越多,为了在合理的时间内完成,单台机器可能会完成不了这个任务,所以我们必须将这个计算压力分担到多个机器上面,并行计算。 但是解决计算的标准化,数据的分配,故障处理,负载均衡等问题是个大工程,让原本简单的代码变得复杂起来。 为此,Google发明了MapReduce系统,隔离了复杂的底层,让程序员能够容易使用这个系统进行大数据量的分布式计算。 编程模型将用户的计算分为两个函数处理:Map和Reduce 函数 Map函数:输入数据,处理后生成一组键值对(中间值) Reduce函数:处理前面得到的中间值,然后将这些值合并在一起,形成更小的值集。通常,每次 Reduce调用只生成零个或一个输出值。 简约模型: 123map (k1,v1) → list(k2,v2)//这里是指对应k2的结果有多个reduce (k2,list(v2)) → list(v2) 举个例子: 现有大量的文本数据,想统计每个单词出现的次数 123456789map(string documentN...

2025-12-18
MIT6.824-Raft-index含义
nextIndex 官方描述:for each server, index of the next log entry to send to that server (initialized to leader last log index + 1) leader保存该数组变量,由leader更新。 nextIndex[i]代表着对第i个follower发起Append Entries RPC时尝试replicated log的位置,仅仅是猜测并不是真实的,并且出现log inconsistency会将该值回退。所以nextIndex[i]需要比matchIndex[i]要大。 leader收到Append Entries RPC回复后只有是因为log inconsistency才能更新nextIndex。 更新nextIndex的三个时机 leader election成功时候,需要更新nextIndex为leader last log index + 1 AppendEntries RPC返回success,代表已经成功replicated log log inconsis...

2025-12-18
MIT6.824-GFS
为什么我们要阅读这篇论文?在分布式系统中,分布式存储是关键的部分,我们该怎么去设计它,分布式存储的interface/semantics 应该怎么定义,它是怎么并行工作的等。 GFS paper涉及到了很多分布式系统主题:parallel performance, fault tolerance, replication, consistency 。从apps到network都有详细的介绍,并且在现实生活中有着成功的应用。 为什么分布式存储这么难? high performance→将数据拆分到很多服务器上面,通过很多台服务器并行读取数据 many servers→机器一多,机器发生故障的概率会变大,需要容灾机制,能够自动恢复 fault tolerance →最简单的方式就是通过复制得到多个副本,当一个副本出现问题时,其他副本还能用 replication →有数据不一致的风险 better consistency →如果需要更强的一致性的话,在网络中所有不同的服务器和客户端之间需要进行很多额外的工作和交流,那么这样性能就会降低,所以这个不是我们最初想要的 我们想要什么样的一...

2025-12-18
MIT6.824-LEC8-Zookeeper
Zookeeper提出了什么问题 能够将coordination作为一种通用服务去提供吗,可以的话,API应该是怎么样的,其他分布式程序应该怎么去使用它? 我们有N个replica server,能从这个N个server中获得N倍性能吗? 将Zookeer视为基于Raft的service只不过ZooKeeper使用的是zab协议,为ZooKeeper专门设计的一种支持崩溃恢复的一致性协议 当我们添加更多的server时候,replication arrangement是否变得更快replica越多,写入的速度就越慢leader必须将每次写入发送给越来越多的server 可以让follower提供只读服务,这样leader压力就小很多可能会产生log与leader不一致的情况,导致client读取的数据不对,甚至是产生“倒退现象”,client先从up-to-date replica读,再从logging replica读。这个就不可能是LinearizabilityRaft和Lab3不会出现这种情况,因为follower不提供只读服务 Zookeeper怎么处理这个在性能和强一...
2025-12-18
MIT6.824-Raft中使用锁的建议
Raft Locking Advicehttp://nil.csail.mit.edu/6.824/2020/labs/raft-locking.txt If you are wondering how to use locks in the 6.824 Raft labs, here are some rules and ways of thinking that might be helpful. 如果您想知道如何在6.824 Raft labs中使用锁,以下是一些可能会有所帮助的规则和思考方法。 规则1:go raceRule 1: Whenever you have data that more than one goroutine uses, and at least one goroutine might modify the data, the goroutines should use locks to prevent simultaneous use of the data. The Go race detector is pretty good at dete...
2025-12-18
MIT6.824-LEC10-Cloud Replicated-DB-Aurora
为什么要学习Aurora 作为近几年成功的云服务,解决了严重的问题 设计良好,有性能的优势 使用general-purpose storage架构情况下的局限性 许多关于云基础架构中重要的内容 Amazon EC2,cloud computing,针对于web 租用直接运行在Amazon数据中心物理机器上的virtual machines instances 使用的存储是连接在物理磁盘上的virtual local disk 客户在EC2上面运行着stateless www server或者DB 但是EC2不适合DB:扩展功能和容错功能有限(可以通过S3大容量存储服务定期存储数据库的snapshot) Amazon EBS (Elastic Block Store) 使用的是Chain Replication,基于paxos的configuration manager 如果DB EC2崩溃,只需要在另一个EC2上面重新启动一个DB并挂载同一个EBS volume EBS不是shared storage,只能由一个EC2挂载 DB-on-EBS缺点 需要通过网络发送大量数...
评论

