MIT6.824-LEC8-Zookeeper
Zookeeper提出了什么问题
- 能够将coordination作为一种通用服务去提供吗,可以的话,API应该是怎么样的,其他分布式程序应该怎么去使用它?
- 我们有N个replica server,能从这个N个server中获得N倍性能吗?
将Zookeer视为基于Raft的service
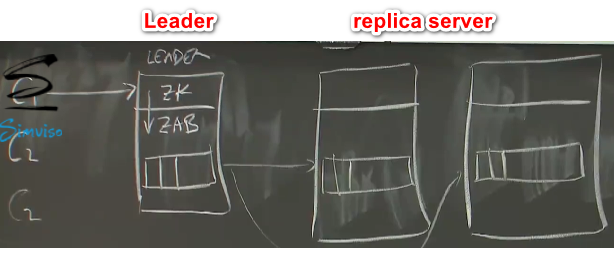
只不过ZooKeeper使用的是zab协议,为ZooKeeper专门设计的一种支持崩溃恢复的一致性协议
当我们添加更多的server时候,replication arrangement是否变得更快
replica越多,写入的速度就越慢
leader必须将每次写入发送给越来越多的server
可以让follower提供只读服务,这样leader压力就小很多
可能会产生log与leader不一致的情况,导致client读取的数据不对,甚至是产生“倒退现象”,client先从up-to-date replica读,再从logging replica读。这个就不可能是Linearizability
Raft和Lab3不会出现这种情况,因为follower不提供只读服务
Zookeeper怎么处理这个
在性能和强一致性之间保持平衡,不提供强一致性,允许从replica读取数据(写只能是写leader),但是在其他方面则是保证了顺序。
Ordering guarantees (Section 2.3)
Linearizable writes
- client发送写入命令到leader
- leader选择一个顺序,编号为
zxid - 将该命令发送给replica,所以replica按照zxid顺序去执行。
- 即使是并发写操作,也会保证按照某个顺序去一一执行。
FIFO client order
client指定write和read操作的执行顺序
- write:按照client指定的write order,section2.3 ready file
- read:
- 每次读都在写入顺序中的某一个点开始执行
- client连续读操作,每次读的顺序保证是非递减,这一次读不会读到前面的内容
- 如果执行读操作的时候,replica挂掉了,client需要将它的读请求发送给另外一个replica,这时候依旧会保证FIFO client order(非递减)。
- 工作原理是每个log entry都有一个zxid,当一个replica响应client的读请求时会携带上一个log entry的zxid(这里的上一个相对于是下一个读请求),client会记住最新数据的zxid,每次请求会携带上zxid。
- 如果另外一个replica也没有最新zxid对应的下一个log,replica可能会延迟对读请求回复直到leader同步了log或者是拒绝这个请求,或者是其他。
- 将write发送给leader,但是leader还没有同步给replica,这时候read replica会被delay(因为指定了命令的执行顺序)或者sync()
- 只是保证了一个client的FIFO order(同一个clien的Linearizability),即同一个client的命令可以保证下一次读到的是上一次的写。但是对于不同的client来讲,client2不一定能准确读到刚刚client1写的数据
尽管Zookeeper不是Linearizability,但是在别的方面还是有用的
- sync()能够让后续不同的client看到之前client写入的值。只有该数据在整个系统中处于写状态,不允许其他client读到。想要读取最新数据,需要sync再读。缺点是增加了leader的处理时间,不这样做的话就不是linearizable
- 场景1 ready file:master在Zookeeper中维护了一个配置文件(描述了分布系统的东西,比如worker ip,master信息等),里面有一堆文件(可以实现原子更新效果),master会去更新配置文件,在更新的过程中worker不能查看配置,只能看到完全更新后的配置。
- 正常的操作序列,虽然不是完全linearizable(只有写),但是读只能往前读,所以达了类似linearizable的效果,提高了性能:

- 正常的操作序列,虽然不是完全linearizable(只有写),但是读只能往前读,所以达了类似linearizable的效果,提高了性能:
- 可能会出现的问题:
读f1的时候,执行了写操作,导致读到的f2不是原来应该读的
Zookeeper使用watch事件去解决,当调用exists的时候,除了判断file是否存在,还在这个文件上面设置了watch事件(replicate会创建watch table,文件修改之前查看watch table),当这个文件被修改时候replica会在一个相对正确的时间点通知client,即会在读操作执行之前。
当replicate crash时候,对应的watch table也会没有,client切换到新的replicate读的时候就不会有对应的watch table。但是client会在合适的时间收到replica崩溃的通知。



几个影响
- 当leader failed时候leader必须保存client的write order(?
- replicate需要保障client的读取顺序按照zxid顺序
- client必须跟踪它已读取的最高 zxid
提高性能的技巧
- client可以让leader发送异步写入,不必等待
- leader可以批处理请求以减少磁盘和网络开销
Coordination as a service是怎么样的(Zookeeper有什么用)
VMware-FT’s test-and-set server
- 要求:一个replica无法和其他replica通信,则获取t-a-s lock(test-and-set lock),成为sole server。必须是唯一的以避免存在两个primary(如果出现network partition),必须是fault-tolerant。
- Zookeeper提供了工具,可以写出fault-tolerant test-and-set服务
Config info
通过Zookeeper发布信息给其他服务使用,比如可以将一组worker中作为当前master的那个ip存放在Zookeeper
Mater elect
在test-and-set server中有体现,master可以把state存放在Zookeeper,如果master crash,选出一个新的maser代替它,新的master可以从Zookeeper中读取旧master的状态。
MapReduce
worker可以注册到Zookeeper中,master会在里面记录着worker的任务,worker会从Zookeeper中将任务一件件拿出来,完成后就会移除掉。
Zookeeper API
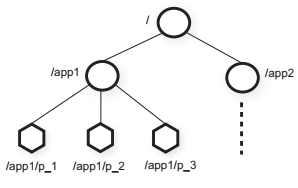
- a file-system-like tree of znodes
each znode has a version number
示例:将一组机器和哪个机器是primary的信息存放在znodes - znode的分类:regular、ephemeral、sequential(file name + seqno)
Operations on znodes
flags:znode type
- create(path, data, flags):互斥的(exclusive),只有第一次创建才能成功
- delete(path, version):if znode.version = version, then delete
- exists(path, watch):设置watch后,当path创建或者删除后会发送一个通知。原子操作,两个write之间的watch不会有任何操作,znode完成改变之前不会收到通知
- getData(path, watch)
- setData(path, data, version):if znode.version = version, then update
- getChildren(path, watch)
- sync()
Zookeeper api可以很好地实现同步
- exclusive file creation:并发创建只有一个能返回成功
- getData()/setData(x, version)支持mini-transactions
- 当client fail的时候,session会自动执行操作,例如失败时release lock
- sequential znode file可用于并发创建的同时又能指定顺序
- watch
znode中的数字递增
mini-transaction保障atomic read-modify-write1
2
3
4while true:
x, v := getData("f")
if setData(x + 1, version=v):
break
当replica不能与leader通信时候,不能退出while循环。只适合少量请求的场景,当有大量的client同时递增时候,性能就会很差,因为同时操作只有一个能完成,复杂度是N^2。使用随机sleep能够减少循环的次数,避免大量的重试。
Simple Locks (Section 2.4)
1 | acquire(): |
在replica exists执行过程中,lock文件被释放掉,会发生什么情况。exists是个只读请求,可能会发生在replica,与此同时,可能会有别的client在执行delete操作。exists会在两个write请求之间执行。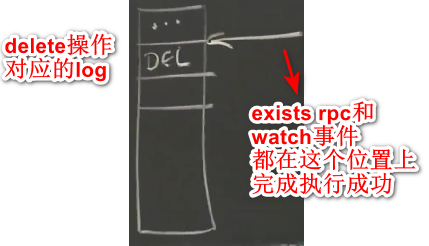
在完成执行成功的时间点,replica会看到lock文件依旧存在,replica会插入watch信息到watch table,然后才执行delete操作。所以当delete操作执行时,确保watch请求会在replica的watch table中,并且replica会给client发送通知。
每次释放锁,所有剩下的client都会收到watch通知,都会返回第一步发送create请求,所以时间复杂度基本上还是N^2。这个就是大量等待client引起的Herd Effect。
Locks without Herd Effect(scalable lock)
1 | 1. create a "sequential" file |
- 大量client请求的话会按顺序产生很多个文件
- 这些文件代表着获得了锁,如果释放了锁则需要删除文件
- 为什么需要list files,因为前一个client可能会failed,导致文件被自动删除,这时候就需要关注上一个的上一个的文件是否存在,而不能只是关注上一个文件(相对于client创建的文件序号,比如client创建了f500,不能只是关注f499)是否存在。
- 如何解决Herd Effect:创建了第501个文件的client在等待第500个文件被释放,创建了第500个文件的client等待第499个文件被释放,每个client都在等待文件被释放。当释放锁的时候,一个client就会收到通知,第三步就会成立,那么这个client就获得了锁。所以一个client的开销只有几次RPC请求的开销,等待锁也可以是异步等待,在另外一个线程通过某种方式查看Zookeeper的状态。其实就相等于锁队列,后一个client都在等待着前面的client释放。
- 如果client持有锁的时候,但是它中途操作失败,那么锁会立即释放,导致下一个client获得锁的时候看到的数据不是正确的数据。所以这些锁和语言带的线程锁相比,它们无法提供相同的原子性保证。
- 基本上使用这种锁有两种考虑:每个获取到锁的client都应该准备好遇到上一个失败这种情况时的操作(比如推断出是在哪个地方出现错误);要么就是保护的数据不是很重要,比如MapReduce中的worker失败后,释放锁后下一个worker执行时看到任务没有完成,重新执行即可。
- 如果client持有锁的时候,但是它中途操作失败,那么锁会立即释放,导致下一个client获得锁的时候看到的数据不是正确的数据。所以这些锁和语言带的线程锁相比,它们无法提供相同的原子性保证。