MIT6.824-Primary-Backup-Replication
What kinds of failures can replication deal with?
- “fail-stop” failure of a single replica
- fan stops working, CPU overheats and shuts itself down
- someone trips over replica’s power cord or network cable(电源线或网络电缆)
- software notices it is out of disk space and stops
- Maybe not defects in h/w(Hardware/Software) or bugs in s/w or human configuration errors
Two main replication approaches
State transfer
- Primary replica executes the service
- Primary sends [new] state to backups
Replicated state machine
- Clients send operations to primary, primary sequences and sends to backups
- All replicas execute all operations
- If same start state, same operations, same order, deterministic, then same end state.
- support only uni-processor (In fact, vmware has a solution for multi-core processor, but it seems to be based on state transfer)
Compared
- State transfer is simpler, but state may be large, slow to transfer over network
- Replicated state machine often generates less network traffice
- Operations are often small compared to state But complex to get right
At what level do we want replicas to be identical
identical: similar in every detail
VMware vSphere Fault Tolerance (VMware FT)replicates the low-level memory and machine registers (Machine level)- might allow us to replicate any existing server without modification
- requires forwarding of machine events (interrupts, DMA(指内存和外设直接存取数据这种内存访问的计算机技术))
- can run any existing O/S and server software. Appears like a single server to clients
- Most like GFS where it was replicating much more application level table of chunks
- Can be efficient; primary only sends high-level operations to backup
- Application code (server) must understand fault tolerance, to e.g. forward op stream
VMware FT
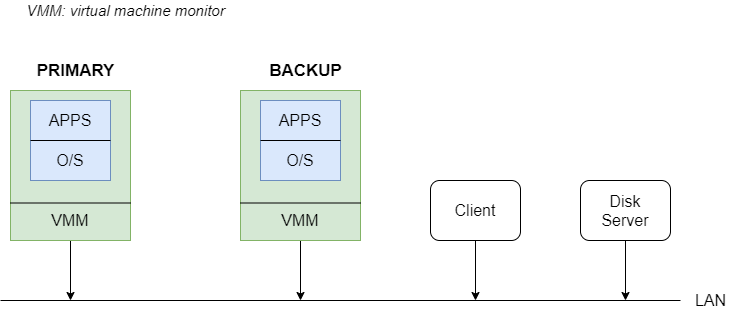
有两台机器,分别是primary和backup,它们都是通过VMM虚拟化运行同一个OS,按照FT来讲,它们运行的内容也是一样的,它们的存储数据的磁盘可能不是在机器上面,而是有个Disk Server,并且有个Client访问数据,这些都通过网路连接在一起。
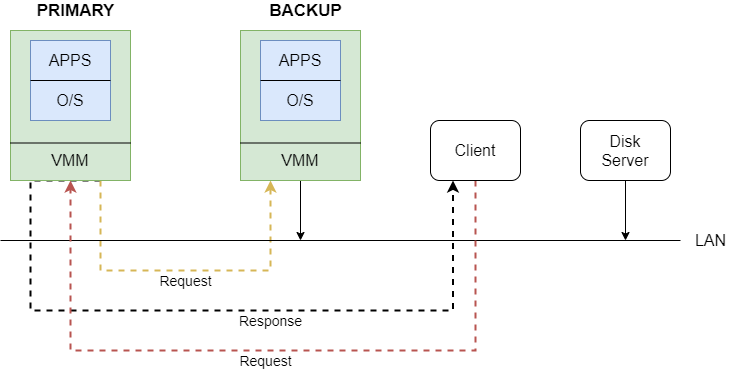
- 现在Client发送一个网络数据包给Primary,Primary的VMM接收到数据包,并产生一个中断,它会模拟一个网络数据包到达的中断给primary上的os,以将这个数据包发送给应用程序。
- 同时VMM还将数据包的副本发送给Backup的VMM,Backup的VMM也会做同样的事情。
- 应用程序会产生Response,并通过VMM所模拟的
NIC (Network Interface Card)将它发送出去。因为Backup也在执行同样的操作,所以Backup也会产生同样的Response,但是FT会将其丢弃,最终只有Primary应答。
Primary将所有external events(网络数据包等)都通过称为Logging channel的网络连接发送到Backup,发送的内容称为log entries
如果Backup超过一定时间没有从Logging channel中拿到数据,那么VMM会让Backup代替Primary。
What sources of divergence must FT handle?
divergence: the process or state of (of opinions or methods) differing
- Most instructions execute identically on primary and backup
- As long as memory+registers are identical, which we’re assuming by induction
- Inputs from external world — just network packets
- These appear as DMA’d data plus an interrupt.
- This interrupt will occur somewhere in the instruction stream. So we must know which instruction occurred when primary and backup behave the same.Otherwise they will be different in execution and the state.
- Instructions that aren’t functions of state, such as reading current time.
- Not multi-core races, since uniprocessor only
- the instructions of the service are interleaved(交错的) in some way which is not predictable(预测的) ( such as get lock)
FT’s handling of timer interrupts
- Goal: primary and backup should see interrupt at the same point in the instruction stream
- Primary
- FT fields(处理) the timer interrupt
- FT reads instruction number from CPU
- FT sends “timer interrupt at instruction X” on logging channel
- FT delivers interrupt to primary, and resumes(恢复) it(this relies on CPU support to interrupt after the X’th instruction)
- Backup
- ignores its own timer hardware
- FT sees log entry before backup gets to instruction X
- FT tells CPU to interrupt (to FT) at instruction X
- FT mimics(模仿) a timer interrupt to backup
FT’s handling of network packet arrival (input)
- Primary
- FT tells NIC to copy packet data into FT’s private “bounce buffer”(When data travels between a device and high memory, it is first copied through the bounce buffer)
- FT gets the interrupt from NIC
- FT pauses the primary
- FT copies the bounce buffer into the primary’s memory
- FT simulates(模拟) a NIC interrupt in primary
- FT sends the packet data and the instruction id to the backup
- Backup
- FT gets data and instruction id from log stream
- FT tells CPU to interrupt (to FT) at instruction X
- FT copies the data to backup memory, simulates NIC interrupt in backup
output rule
Avoid data inconsistency caused by backup not receiving log after primary crash
- Primary:
- receives client “increment” request
- sends client request on logging channel
- about to(即将) send reply to client
- first waits for backup to acknowledge(承认) previous log entry
- then sends reply to client
what if the primary crashed after emitting the output? Will the backup emit the output a second time?
Yes.
OK for TCP, since receivers ignore duplicate sequence numbers.
OK for writes to disk, since backup will write same data to same block id.
could it suffer from split brain
The disk server breaks the tie.(打破了僵局)
Disk server supports atomic test-and-set.
If primary or backup thinks other is dead, attempts test-and-set.
If only one is alive, it will win test-and-set and go live.
If both try, one will lose, and halt.