
MIT6.824-LEC10-Cloud Replicated-DB-Aurora
为什么要学习Aurora
- 作为近几年成功的云服务,解决了严重的问题
- 设计良好,有性能的优势
- 使用general-purpose storage架构情况下的局限性
- 许多关于云基础架构中重要的内容
Amazon EC2,cloud computing,针对于web

- 租用直接运行在Amazon数据中心物理机器上的virtual machines instances
- 使用的存储是连接在物理磁盘上的virtual local disk
- 客户在EC2上面运行着stateless www server或者DB
- 但是EC2不适合DB:扩展功能和容错功能有限(可以通过S3大容量存储服务定期存储数据库的snapshot)
Amazon EBS (Elastic Block Store)
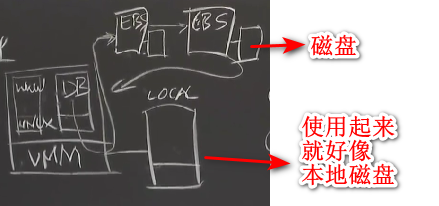
- 使用的是Chain Replication,基于paxos的configuration manager
- 如果DB EC2崩溃,只需要在另一个EC2上面重新启动一个DB并挂载同一个EBS volume
- EBS不是shared storage,只能由一个EC2挂载
DB-on-EBS缺点
- 需要通过网络发送大量数据—log和dirty data pages,即使只是几bytes的更改,data pages也很大,可能一个page是8k
- 为了性能,两个replica放在同一个”availability zone” (AZ)—machine room or datacenter,AZ挂了则数据库都挂了
generic transactional DB
示例:单机,x账户转账10元到y账户,在事务执行期间,x和y将被锁住,直到commit完成后释放,事务完成后数据就被持久化。1
2
3
4begin
x = x + 10
y = y - 10
end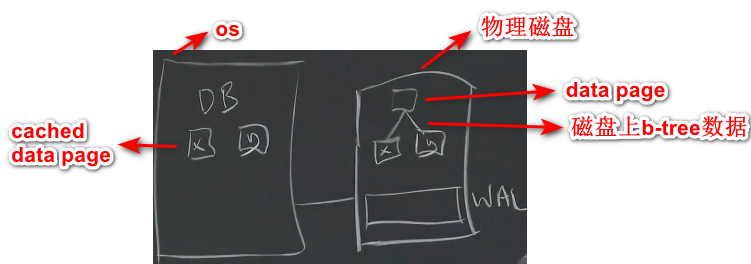
- WAL(Write-Ahead Log):让系统实现容错能力的关键部分
- DB server在事务运行时只会修改cached data page,并将更新信息(log entry)添加到WAL

- 安全提交WAL到磁盘后,释放x和y的锁,并回复给client
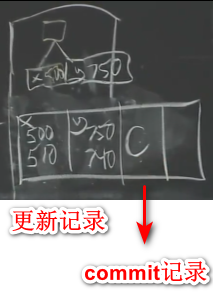
- 随后将修改后的data page从缓存写入到磁盘,但是数据库一般会积累很多未写入磁盘的值在cache上面。当db crash后重启,会扫描commit记录,执行redo和undo操作。
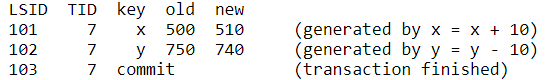
- 需要在WAL保存旧值,当崩溃恢复的时候,需要undo回滚到旧值。
Multi-AZ RDS
database-as-a-service,而不是客户自己运行db在EC2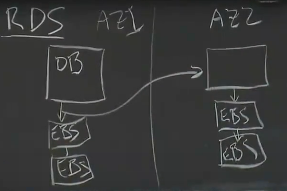
- 目标:通过cross-AZ replication实现更好的容错能力
- 每个写数据必须发送到本地EBS和另外一个EC2上运行的DB,包括log entry和所有的dirty data pages
- 数据库写入必须等待四个EBS完成后才能回复给client,所以数据量大的话这里会有很大的延迟,但是容错性更好。
Aurora的做法
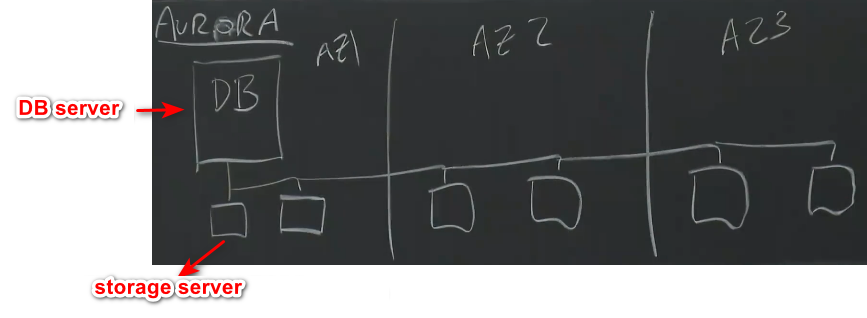
- 一个DB server(使用EC2实例),底层对应着6个replica(storage server,其实就是挂载着一个或两个硬盘的server instance)
- 但是6个replica并不比RDS慢,因为只需要发送log entry(small),而不用发送dirty data pages(big)。但是这里并不是通用的,只能处理MySQL的log entry,EBS则具有通用,因为只是一个磁盘。
- 不需要让6个replica都确认写请求,只要有Quorum(达到法定确认人数,事实证明只需要任意4个,简单的来说,在写操作时候,可以忽略最慢或者基本死掉的replica),数据库服务器就能够继续运行。
- 35x throughput increase,可能主要是因为发送的数据少得多,但是增加了cpu和存储的使用量。
Aurora’s storage fault tolerance goal
- 即使一个AZ完全死了也能处理写请求
- 即使一个AZ完全死了+另外一台server发生故障,也能够处理读请求
- 即使在某些存储服务器变慢或者暂时不可用情况下,服务也能够继续进行
- fast re-replication(快速复制出另外一个replica或者修复dead replica)
Quorum read/write technique
- 目标:fault-tolerant storage,即使出现一些failures也能够读取最新的数据
- 通常应用于简单的read/write (put/get) storage
- 需要配置N、W、R(N replicas, writes to any W replicas, reads from any R replicas),W和R的replica需要有一台重叠(overlap,也就是R+W=N+1),即负责写也负责读
- 示例:N=3, W=2, R=2
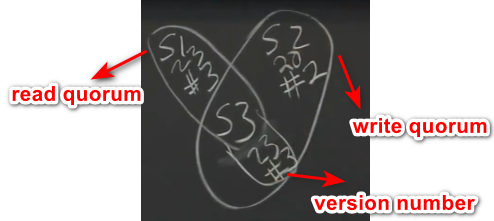
- 发出一个写请求,将值更新为23
- 得写入W个replica
- 接着处理读请求,为了处理读请求,至少得包含一个处理过写请求的server
所以overlap确保了至少有1个来自write quorum
- read quorum对应的server有多个,如何确定从哪个server中读取到的是最新数据?
采用版本号机制,最大版本号的就是最新的数据,不能采用投票机制,可能read quorum中只有一个数据是最新的。 - read/write quorum不能达到指定人数怎么办?继续重试
quorum read/write storage systems有什么好处
- 可以轻易处理dead or slow or partitioned storage servers,不需要等待、检测、超时机制等并且也不存在split brain风险。
- 可以调整R和W以使读/写更快,比如可以使R=1,W=3,这样读起来更快,只需要等待一台机器响应即可,反过来写则会慢很多。但是Aurora容错能力是min(N-W, N-R),这里的值是0,所以就没有容错能力。
Aurora的N、W、R是怎么样的
N=6,W=4,R=3
一个AZ完全死掉之后剩余4个replica,W=4,可以继续写入
一个AZ完全死掉+一个server死掉后,剩余3个replica,R=3,可以继续读取
Aurora是怎么样写入的
- DB server写入storage servers时候不会修改现有的数据项,而是写入新的log entry,即写操作或者事务完成之前,这条日志记录至少已经落地到4台server上面。达到Write Quorum后才会对client进行响应。
- 确定一个事务之前,需要等待Write Quorum的storage server对之前所有提交的事务响应之后,才会响应现在这个事务。崩溃恢复也是如此,需要先恢复前面的事务。
storage server如何处理传入的log entry
- 拿到的只是对data page修改的日志,并没有data page
- storage server内部保持了数据库中data page在某一时刻的数据(旧版本),所以实际上存储的是旧版本的data page和更新page所需要的日志列表
- storage server异步或者在需要读取日志的时候apply这些日志到page,然后将data page返回
Aurora的读是怎么样的
- 写入的是log entry,读取的是data page(cached data page is missed)。实际上,DB server会跟踪每个storage server收到了多少个log entry,读取的时候只需要从有最新的server里面读即可,不需要Read Quorum(写入需要Write Quorum)。
- 当DB server(不是storage server)崩溃恢复的时候,会自动在不同的EC2示例上重新启动一个DB server。
- 崩溃的DB server可能处于处理某组事务的状态上,一些事务已经执行完成数据保存在Quorum上面,还有一些执行到一半的事务(一些数据可能已经保存到了某一个server上,而有的server可能还没有),所以重新启动的DB server需要读取Read Quorum,会在这些storage server上找到缺失日志编号最高的那个log entry,并告诉storage server丢失后续所有的日志。
- 所以可能存在一些半路崩溃保存下来的没有提交的日志(只有更新记录,没有commit记录标志),DB server需要检测出这些日志,并执行undo操作
如何处理解决太大而无法存储在storage server的问题

- data page被分片(每片大概10GB)存储在Protection Groups (PGs)上,比如将B-Tree中编号为奇数的data page放到PG1,偶数的放到PG2
- 每个PG由6个replica组成,不同的PG可能位于不同集群(sets of six storage servers),这些server由Aurora客户共同使用。
- 如何拆分log:当DB server发送log entry时候,会根据log中所修改的数据查到保存该数据的PG,然后将日志发送给PG。所以每个PG存储了部分data page+这部分data page进行提交的日志记录。
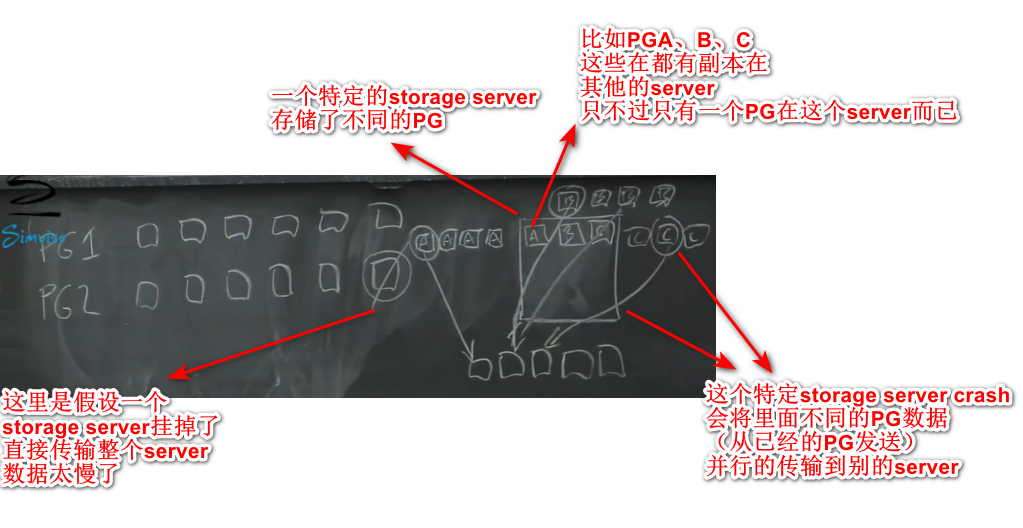
当storage server crash时候如何快速替换
- 需要快速替换,避免接着有更多的server崩溃,导致无法恢复
- 可能crash掉的storage server里面保存了1000个PG(假设每个硬盘10T)replica,这可能会导致其他客户的10G PG数据也不可用,所以需要复制的是整个硬盘上的数据。假设内网的网速是10Gb/s,那么传输需要10000秒。
- 当发生特定storage server crash时候,假设这里面存储了PGABC的数据,处理程序会将PGABC其他replica里面的数据发送到另外几台server,并行的恢复需要的时间很少。不过当发生很多server都crash时候,这种方法也不奏效,只能通过单台机器恢复。
只读实例
- master只负责写,同时存在很多只读replica(R/O),以减少master的负载
- R/0从storage server读取data page,并缓存data page,master将log发送给R/O保持缓存的data page是最新的。
- master需要在log中标注uncommitted log,R/O则需要直到这些transaction commit后才应用到缓存中。
- replica在storage server直接读数据的时候可能会看到B-Tree正在执行平衡或者一些其他操作,所以storage server得展示已完成事务后对应的data page,不能是未完成的,需要对B-Tree加锁之类的。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 GreenHatHGのBlog!
相关推荐

2025-12-18
MIT6.824-LEC11-Cache-Consistency-Frangipani
为什么要阅读这篇论文 cache coherence distributed transactions distributed crash recovery 三者的相互作用 整体的设计 a network file system,与现有的应用程序共同工作,类似普通的unix程序。可以将petal想象成一个磁盘,通过网络将数据共享给Frangipani,看起来就像从普通磁盘上读取数据 预期用途 一个文件系统,能保存自己的home目录以及共享的项目文件,在任何的workstation(可以理解是个人PC)能拿到自己的home目录以及所需要的所有文件。 没有涉及到安全问题,彼此电脑之间互相信任,适用于小群体 Frangipani的设计 强一致性 caching in each workstation — write-back 所有对文件的更新最初只是在workstation cache中完成—速度快 包括创建文件、目录、重命名等 比如ws1(workstation user 1)想要创建并读写/grades:Frangipani会从Petal读取/infomation的信息并保存...
2025-12-18
MIT6.824-MapReduce
背景有时候我们需要从一批数据中得到一些结果,比如从最频繁查询的结果集,每个单词出现的次数。随着输入的数据越来越多,为了在合理的时间内完成,单台机器可能会完成不了这个任务,所以我们必须将这个计算压力分担到多个机器上面,并行计算。 但是解决计算的标准化,数据的分配,故障处理,负载均衡等问题是个大工程,让原本简单的代码变得复杂起来。 为此,Google发明了MapReduce系统,隔离了复杂的底层,让程序员能够容易使用这个系统进行大数据量的分布式计算。 编程模型将用户的计算分为两个函数处理:Map和Reduce 函数 Map函数:输入数据,处理后生成一组键值对(中间值) Reduce函数:处理前面得到的中间值,然后将这些值合并在一起,形成更小的值集。通常,每次 Reduce调用只生成零个或一个输出值。 简约模型: 123map (k1,v1) → list(k2,v2)//这里是指对应k2的结果有多个reduce (k2,list(v2)) → list(v2) 举个例子: 现有大量的文本数据,想统计每个单词出现的次数 123456789map(string documentN...
2025-12-18
MIT6.824-Raft中使用锁的建议
Raft Locking Advicehttp://nil.csail.mit.edu/6.824/2020/labs/raft-locking.txt If you are wondering how to use locks in the 6.824 Raft labs, here are some rules and ways of thinking that might be helpful. 如果您想知道如何在6.824 Raft labs中使用锁,以下是一些可能会有所帮助的规则和思考方法。 规则1:go raceRule 1: Whenever you have data that more than one goroutine uses, and at least one goroutine might modify the data, the goroutines should use locks to prevent simultaneous use of the data. The Go race detector is pretty good at dete...

2025-12-18
MIT6.824-Primary-Backup-Replication
What kinds of failures can replication deal with? “fail-stop” failure of a single replica fan stops working, CPU overheats and shuts itself down someone trips over replica’s power cord or network cable(电源线或网络电缆) software notices it is out of disk space and stops Maybe not defects in h/w(Hardware/Software) or bugs in s/w or human configuration errors Two main replication approachesState transfer Primary replica executes the service Primary sends [new] state to backups Replicated state mach...
2025-12-18
MIT6.824-Raft-index含义
nextIndex 官方描述:for each server, index of the next log entry to send to that server (initialized to leader last log index + 1) leader保存该数组变量,由leader更新。 nextIndex[i]代表着对第i个follower发起Append Entries RPC时尝试replicated log的位置,仅仅是猜测并不是真实的,并且出现log inconsistency会将该值回退。所以nextIndex[i]需要比matchIndex[i]要大。 leader收到Append Entries RPC回复后只有是因为log inconsistency才能更新nextIndex。 更新nextIndex的三个时机 leader election成功时候,需要更新nextIndex为leader last log index + 1 AppendEntries RPC返回success,代表已经成功replicated log log inconsis...

2025-12-18
MIT6.824-LEC8-Zookeeper
Zookeeper提出了什么问题 能够将coordination作为一种通用服务去提供吗,可以的话,API应该是怎么样的,其他分布式程序应该怎么去使用它? 我们有N个replica server,能从这个N个server中获得N倍性能吗? 将Zookeer视为基于Raft的service只不过ZooKeeper使用的是zab协议,为ZooKeeper专门设计的一种支持崩溃恢复的一致性协议 当我们添加更多的server时候,replication arrangement是否变得更快replica越多,写入的速度就越慢leader必须将每次写入发送给越来越多的server 可以让follower提供只读服务,这样leader压力就小很多可能会产生log与leader不一致的情况,导致client读取的数据不对,甚至是产生“倒退现象”,client先从up-to-date replica读,再从logging replica读。这个就不可能是LinearizabilityRaft和Lab3不会出现这种情况,因为follower不提供只读服务 Zookeeper怎么处理这个在性能和强一...
评论

