MIT6.824-GFS
为什么我们要阅读这篇论文?
在分布式系统中,分布式存储是关键的部分,我们该怎么去设计它,分布式存储的interface/semantics 应该怎么定义,它是怎么并行工作的等。
GFS paper涉及到了很多分布式系统主题:parallel performance, fault tolerance, replication, consistency 。从apps到network都有详细的介绍,并且在现实生活中有着成功的应用。
为什么分布式存储这么难?
high performance→将数据拆分到很多服务器上面,通过很多台服务器并行读取数据many servers→机器一多,机器发生故障的概率会变大,需要容灾机制,能够自动恢复fault tolerance→最简单的方式就是通过复制得到多个副本,当一个副本出现问题时,其他副本还能用replication→有数据不一致的风险better consistency→如果需要更强的一致性的话,在网络中所有不同的服务器和客户端之间需要进行很多额外的工作和交流,那么这样性能就会降低,所以这个不是我们最初想要的
我们想要什么样的一致性?
- Ideal model: same behavior as a single server
- server uses disk storage (persistence)
- server executes client operations one at a time (even if concurrent)
假设现在有两个客户端C1, C2,C1发送一个写请求,想将X的值设置为1,同时,C2也发送一个写请求,想把X的值设置为2。C1, C2都完成后,有两个客户端C3, C4想要读取X的值,会发生什么
显然这里两个客户端读到的值是不确定的,1或者2,因为没有定义服务器处理写请求的顺序。但是C3和C4得到的值必须是一样的,这就是强一致性模型。
在多副本中强一致性变得麻烦起来,一个简单但是很糟糕的复制方案:
现有两个副本服务器S1和S2,现在两个客户端同时向两者发送写请求。
C1将S1和S2中的X设置为1,C2将S1和S2中的X设置为2
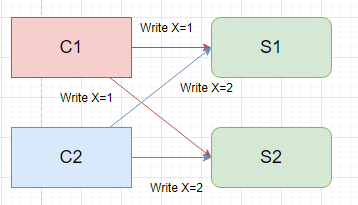
在这里我们并没有做任何事情来保证两个服务器是以同样的顺序来处理这两个请求。
如果S1先接受C1的设置,那么X先被设置为1,接着处理C2,那么X就被覆盖为2;如果S2处理的顺序反过来的话,S2的X会为1,那么读取到的数据就会不一致。或者是S1已经写数据了,但是S2突然崩溃了,没有执行成功,这样数据也会不一致。
更好的一致性通常需要确保副本之间的同步,这可能会有性能问题,所以这个得看使用者对一致性的接受程度。
GFS
背景
在2003年时候Google file system论文发表,是第一个用分布式学术思想落地的应用,虽然在此之前十年已经有分布式的研究了。
Google许多服务都需要用到大型且快速的存储系统去存储或者读取大量数据集,比如MapReduce、索引、日志存储/分析、Youtube视频等。
这个系统是通用或者全局可复用的,允许在应用程序之间共享数据:
- 为了提高并行性能和增加可用空间,在多个服务器/磁盘上自动“切分”每个文件
- 自动从故障中恢复
- 单个GFS是运行在一个数据中心或者一个大型机房,虽然部署全球副本很有价值,但是这个很难
- GFS仅面向Google内部使用,但是会向外出售使用了GFS的服务,并不会直接出售GFS
- 旨在用于大文件(GB或者TB级别)的顺序访问和写入,而不是随机访问小文件
- 没有把重点放在低延迟上面,而是放在大吞吐量上面,比如几MB大小的操作
论文在当时的优点
- 构建的系统是比之前的类似的论文中所描述的系统要庞大得多
- 有着实践的经验
- 证明了弱一致性是ok的,借此获得更好的性能
- 单master成功应用。单个master可以让一致性更强,多个的话难维护较强的一致性,但会带来别的提升。
架构
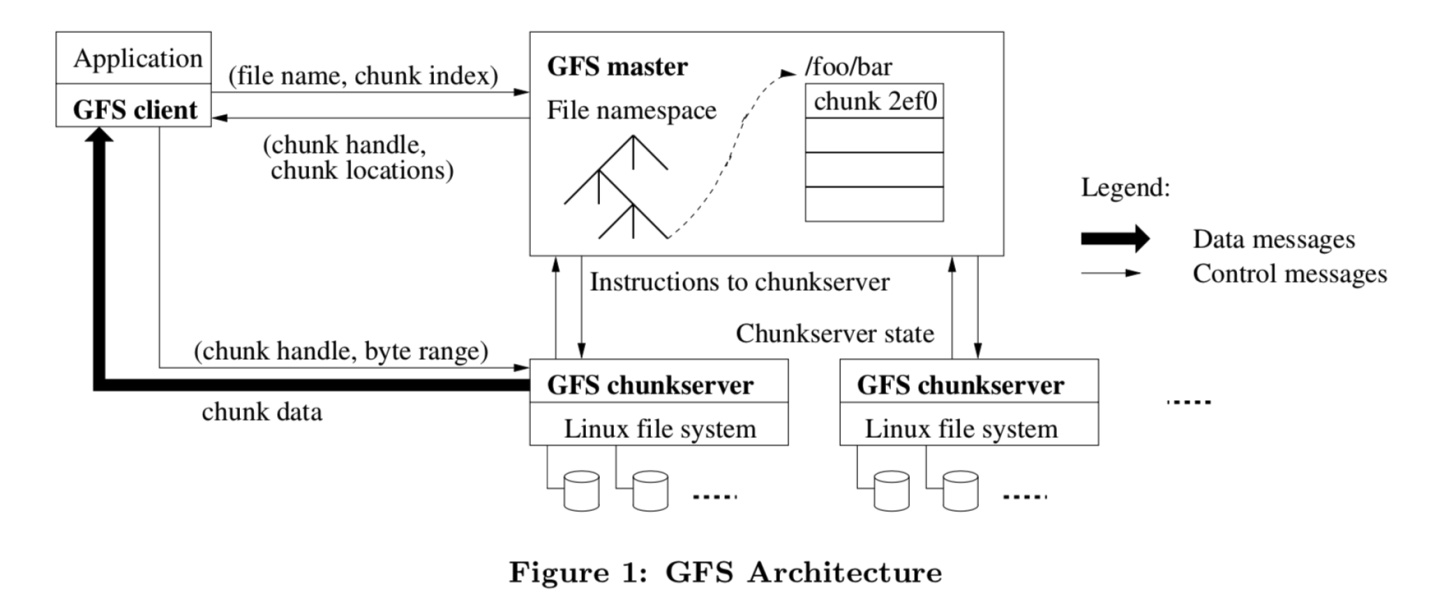
GFS由一个master和多个chunkserver组成。
- 文件被分成固定大小的
chunks,每个chunk都是64MB大小。每一块都由一个不可变的、全局唯一的64位chunk handle标识,这个标识在块chunk创建的时候由master分配 - master会维护文件名和数据保存位置之间的关系,用来命名文件和查询这些chunk的位置信息
- chunkserver用来保存实际数据的
Master Data
主要保存两个映射关系,nv:非易失性:
- file name→array of chunk handles (nv):去哪里找这些数据或者这些chunk的标识符是什么
- chunk handle→list of chunkservers (v):每个chunk有多个副本,这里不需要持久性,当master重启后,master会和所有的chunkserver通信以确定这些信息
- version (nv):每个chunk都有一个version
- primary (v):有许多个副本,primary是其中的一个,master需要记住primary chunk对应的chunkserver,但是这个信息不需要存储,master可以等待60s后lease过期,然后再指定一个primary
- lease expiration:master会记住lease的过期时间
这些数据读是在内存中进行,但是写会写到磁盘中(实际上保存的是操作日志),当日志达到一定大小时,master会建立checkpoint,当master重启后,会恢复到最近的checkpoint。
这些日志使用文件存储,而不使用数据库存储,是因为在磁盘上面它们有些是用B树或者哈希表进行组织的,这样的对日志进行追加操作时候会非常高效(当磁盘磁臂旋转到一个位置时,可以写入大量的数据,而数据库存储并不考虑顺序,要符合真实的b树需要去寻找再追加)。
读操作
- Client向Master发出读请求,通过一个文件名和一个文件中的偏移量(
offset)找到它想要的数据的范围。 - Matser根据这两个信息查之前保存的映射关系表得到chunk handle列表和chunkserver列表,并返回,Client会缓存该信息。
- Client向最近的chunkserver发送请求,包括chunk handle和offset,chunkserver读取磁盘上的chunk数据并返回
追加操作
- Client询问Master文件最后一个chunk
- 写操作Master都是和Primary通信,如果此时没有Primary(或者lease已经过期):
- 需要等待Master找出需要的一组有着最近chunk的chunkservers
- 从中选择一个作为Primary,其他作为Secondary
- 递增版本号,写入磁盘
- 告诉所有副本它们是P(Primary)还是S,以及最新的版本号
- 副本将最新版本号写入磁盘
- Master回复Client Primary和Secondaries的位置,然后
- Client向Primary和Secondaries发送要追加的数据,拿到数据后只是将这些数据写到临时区域上。一旦所有副本都确认接收到了数据,Client就向Primary发送写请求。
- Primary会检查lease是否还未过期,同时检查chunk是否还有空间。
- Primary选择一个offset(at end of chunk),将数据写入到chunk中(Linux文件)。同时Primary会向Secondaries传递offset,让它们追加数据到chunk中。
- Primary会等待Secondaries的回复,可能是”Yes“,”error”或者timeout。如果全部写入成功,则返回成功给Client,否则回复”error”。
- 如果收到error,Client会重试追加操作