MIT6.824-MapReduce
背景
有时候我们需要从一批数据中得到一些结果,比如从最频繁查询的结果集,每个单词出现的次数。随着输入的数据越来越多,为了在合理的时间内完成,单台机器可能会完成不了这个任务,所以我们必须将这个计算压力分担到多个机器上面,并行计算。
但是解决计算的标准化,数据的分配,故障处理,负载均衡等问题是个大工程,让原本简单的代码变得复杂起来。
为此,Google发明了MapReduce系统,隔离了复杂的底层,让程序员能够容易使用这个系统进行大数据量的分布式计算。
编程模型
将用户的计算分为两个函数处理:Map和Reduce 函数
Map函数:输入数据,处理后生成一组键值对(中间值)Reduce函数:处理前面得到的中间值,然后将这些值合并在一起,形成更小的值集。通常,每次 Reduce调用只生成零个或一个输出值。
简约模型:
1 | map (k1,v1) → list(k2,v2) |

举个例子:
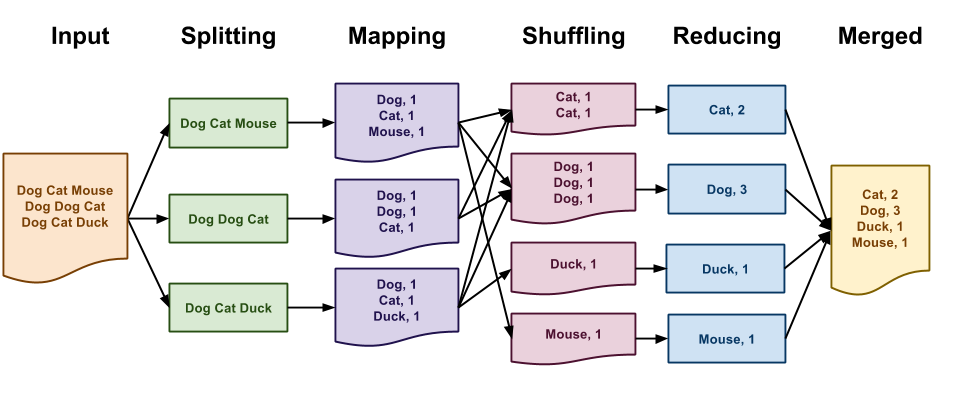
现有大量的文本数据,想统计每个单词出现的次数
1 | map(string documentName, string documentValue): |
Map函数统计每个单词及其出现的次数(假设只有1)。Reduce 函数将计算每个特定单词出现的总次数。
实际上,我们会将要输入的数据分割成多份,Map和Reduce函数也会起多个进程,这样能够更快的处理任务,如下图
实现
执行概述
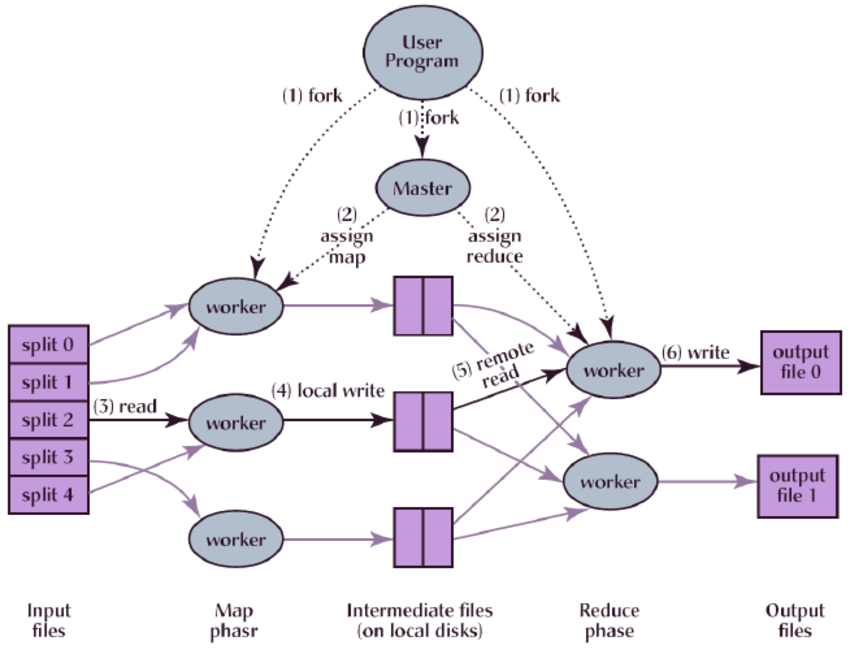
上面是论文中MapReduce运行程序的总体流程,当用户程序调用 MapReduce 函数时,会有以下操作(编号对应上图中的编号)
- 用户程序中的MapReduce库首先将输入文件拆分为
m片,每片通常为 16 到 64 MB(用户可以通过一个可选参数进行控制)。然后,它在三台机器上启动多个程序副本。 - 其中有一个是主程序(
Master),它会管理其余的程序(Worker),Master主要作用是分配一个Map或一个Reduce任务给闲置的Worker程序(假设有M个Map任务和R个Reduce任务) - 有Map任务的Worker 会输入相应的分割后的内容,接着解析输入数据中的键值对,并将每个键值对传递给用户定义的Map函数。Map 函数生成的中间键/值对在内存中进行缓冲
- 缓存会定期写入到本地磁盘(磁盘通过分区函数被划分为R个区域)。本地磁盘上有数据的区域的位置信息会被上传给Master,Master负责将这些位置信息传递给Reduce 任务的Worker
当有Reduce 任务的Worker 接收到Master 传递过来的位置信息时,它会使用
RPC从Map Worker 的本地磁盘读取缓冲数据。读取了所有的中间数据后,它会按照中间键对其进行排序,以便将出现的所有同一个键组合在一起。如果中间数据量太大,内存无法容纳,则使用外排序。外排序(External sorting)是指能够处理极大量数据的排序算法。 通常来说,外排序处理的数据不能一次装入内存,只能放在读写较慢的外存储器(通常是硬盘)上。
- Reduce Worker遍历排序后的中间键值对数据,对每个特定的key,会将key和相对应的中间值集合传递给用户定义的Reduce函数。Reduce函数的输出会写到对应的分区文件中。
- 当所有的Map和Reduce任务完成后,Master会唤醒用户程序。此时,用户程序中的MapReduce调用会返回。
一般完成之后并不是将这些分文件合并,而是将这些文件作为输入传递给另一个MapReduce调用,或者从另一个分布式应用程序使用它们。
Master结构
对于每个Map和Reduce任务,Master存储了这些任务的状态(闲置,进行中,已完成)以及有非闲置状态任务的Worker的标识。
对于每个已完成的Map任务,Master存储了Map任务产生的R个中间键值对文件的位置和大小。当有Map任务完成时,将更新位置和大小信息,这些信息将会推送给正在Reduce操作的Worker。
容错
Worker故障
Master会定时给Worker发送信号,如果在一定时间内没有收到回复,则将该Worker标记为故障状态。任何Map任务或Reduce任务在失败的Worker上运行时会被重置为空闲状态并有资格进行重新调度。
已经完成的Map任务在故障时会重新执行,因为它们的输出在故障的Worker本地磁盘中,不可访问。已经完成的Reduce任务不需要重新执行,因为它们的输出存储在全局文件系统中。
假设有一个Map任务首先由Worker A执行,A出现了故障,然后由Worker B执行,执行Reduce任务的Worker会得到重新执行的通知。任何还没有从Worker A读取数据的Reduce任务将从Worker B读取数据。
如果是大量的Worker同时出现故障,MapReduce只是简单得重新执行无法访问的Worker机器所做的工作,并接着往下执行任务,最终完MapReduce的任务。
Master故障
如果Master出现故障 ,则可以从上一个checkpointed状态启动新的副本。但是由于只有一个master,它出现故障的可能性很小。因此,如果Master失败,目前的实现是将中止MapReduce 计算。如有需要,可以执行重试操作。
存储
因为网络带宽是比较昂贵的,可以用分布式文件系统(这里用GFS)去管理数据。GFS 将每个文件按 64MB 分块,并在不同的计算机上存储每个块的几个副本(通常是 3 个副本)。
Master尝试在包含相应输入数据副本的机器上面安排Map任务,如果不行,则尝试将Map任务安排在任务输入数据的副本附近(例如,同一个网络交换机),所以相当一部分Worker输入的数据都是在本地读取的,不消耗网络带宽。
备份任务
一个比较常见的问题是部分机器计算任务所需的时间过长,导致整个MapReduce的执行时间过长,这可能是各种各样的问题导致,比较常见的是CPU、内存、本地磁盘等资源的竞争。
有一个通用的解决方法是:当一个MapReduce计算接近完成时,Master会调度一个备用(backup)任务来执行剩下的处于正在执行中(in-progress)的任务。无论是这个主任务还是这个备用任务完成了,我们都会将这个任务标记为完成。
Lab1
主要任务
在本地的一台机器上实现一个简易版本的MapReduce ,它由两个程序(Master和Worker)组成,只有一个Master,一个或多个Worker进程并行执行。每个Worker进程都会向Master索要任务,从一个或多个文件中读取任务的输入,执行任务,并将任务的输出写入一个或多个文件。这里的故障点只是简单的判断Worker是否在10s内完成任务,如果没有按时间完成则将该任务分配给其他可用Worker继续执行。
主要流程
一开始拿到代码有点无从下手的感觉,我们得弄清楚代码的框架。
测试
首先得知道是怎么跑起来的,Lab1提供了一个测试脚本test-mr.sh ,里面会有几个测试点,它会通过这几个测试点检测你的代码是否编写正确,值得一提的是最后一个测试点就是模拟了故障情况,它会在每个Worker中执行一个函数,这个函数有几率会让Worker进程退出(os.Exit(1))或者让执行时间大幅延长(time.Sleep) 。
测试脚本主要是作了一下工作:
- 清除历史执行产生的数据文件
- go build代码
- run一个Master和多个Worker进程
- 产生正确的文件以及对比你的代码在该测试点下输出的文件是否一致
- 直到所有的测试点完成
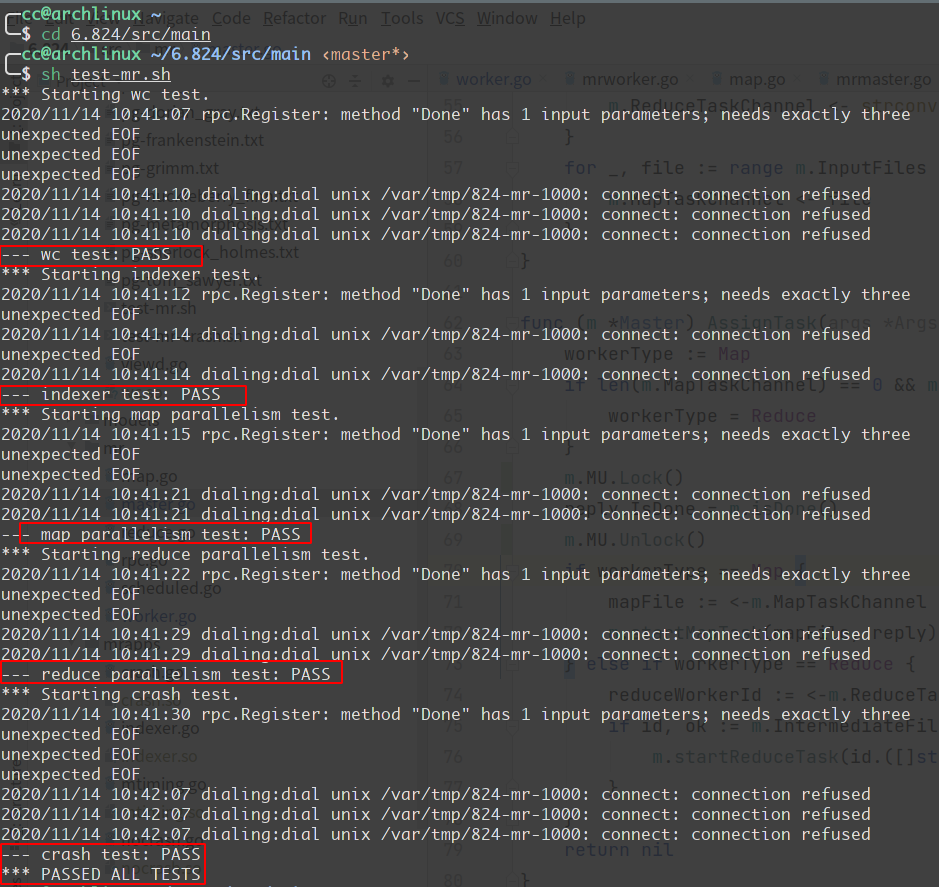
调用流程
src/main/mrsequential.go 里面提供了单进程版本,主要用于测试点生成正确的输出文件,我们写代码时可以随意从里面拿代码。
与我们写代码有关系的是src/main/mrmaster.go src/main/mrworker.go 以及src/mr 里面的所有文件
- 测试脚本启动一个
src/main/mrmaster.go进程,该进程主要是用于传递「要处理的文件列表」以及「ReduceWorker的个数」给src/mr/master.go里面的MakeMaster函数 - 启动多个
src/main/mrworker.go进程,主要用于执行src/mr/worker.go里面的Worker函数。
所以到这里我们大概直到了我们要编写的代码就是位于src/mr/master.go 和src/mr/worker.go,脚本只是把必要的信息传给我们和启动对应的进程,所以我们要编写的主要代码如下:
- Master分配任务给Worker(Map和Reduce任务)
- Worker处理任务,一直到Map任务或者Reduce任务完成
- Master对Worker容错处理,当出现Worker超时未完成时,及时将任务分配给其他的Worker
注意事项
- RPC请求和返回的结构体字段首字母必须大写,否则拿到的值为空
- 对必要的操作加锁,因为涉及到并发操作
- 该实验先执行完所有的Map任务再执行Reduce任务,但是Worker还是那一些,只不过不同任务而已
- 每次执行任务都需要带上不同的id,即使是同一个Worker,因为生成的中间文件命名需要用到该id,如果id相同则可能会把之前生成的文件给覆盖掉
Master实现
刚开始是用两个slice作为队列分别保存输入文件列表(InputFiles)和中间文件列表(IntermediateFiles),主要处理流程如下:
- 从InputFiles取文件作为Map任务分配到各个Worker
- Map任务完成则调用Master的方法将返回的中间文件名放到IntermediateFiles
- 直到InputFiles为空,接着对中间文件分类,按照文件名分配好Reduce任务
- 从IntermediateFiles取文件作为Reduce任务分配到各个Worker
- 任务处理完成
Worker中提供了ihash函数,能够根据key(单词)分配Reduce Worker,所以按照mr-X-Y规则生成的中间文件列表如下,按照Y 我们可以分类文件给不同的Reduce Worker
上面方案有几个缺点:
- 没有对Worker进行容错处理,所以还需要额外的队列保存Worker,出错时把重新放到队列,这里三个队列的同步关系不好处理,因为是并发,加锁并不是那么好加
- 用队列保存中间文件还得分类,如果出错了又得重新放回队列,重新取,代码上繁琐了点。
针对上面的并发和繁琐问题,做了下面更改
IntermediateFiles用sync.Map代替,key为ReduceWorkerId,Value为待处理文件列表- 使用
channel作为中间缓冲层处理Map和Reduce的通信 - 同时使用一个
sync.Map记录Task信息,key为WorkerId,主要有两个状态:空闲和进行中,每次启动一个任务,则开启个十秒的定时任务,如果检测到没有完成,则将该Worker变为空闲状态,并将任务文件列表放到对应的channel
sync.Map和channel的优势是并发下保证数据的一致性,节省了很多加锁操作
Worker实现
Worker实现则是根据Master的任务来选择执行Map或者是Reduce任务,具体的对文件处理逻辑可以直接参考单进程版本
核心代码
channel初始化
MakeMaster后,将输入文件放到MapTaskChannel ,将要执行reduceWorkerId放到ReduceTaskChannel
1 | func (m *Master) putTask() { |
Worker
Worker这部分比较简单,请求任务,并根据任务类型分发任务,执行完后再不断请求,直到任务请求完成
1 | func Worker(mapf func(string, string) []KeyValue, reducef func(string, []string) string) { |
Master分配任务
这里是最核心的了
这里首先执行的Map任务,channel中没有了Map任务而且所有的Map任务都执行完成,则执行Reduce任务。
执行Map任务也比较简单,就是从channel里面拿一个任务,Reduce也同理,只不过MapTaskChannel拿到的是文件,ReduceTaskChannel拿到是具体执行哪个ReduceWorker。
1 | func (m *Master) AssignTask(args *Args, reply *TaskReply) error { |
这里执行检测Map或者Reduce是否都已经执行完成
1 | func (m *Master) checkTaskIdle(workerType WorkerType) bool { |
这里是检测全部任务是否完成
1 | func (m *Master) isDone() bool { |
MapTaskFinish
Map任务执行完后告诉给Master,然后Master将中间文件记录,这里用了sync.Map,记录同时分类
记录完后调用initTaskState 初始化Worker为空闲状态
1 | func (m *Master) MapTaskFinish(args *MapFinish, reply *TaskReply) error { |