项目Golang优化点
一、前言
最近接手的一个项目需要预先生成大量缓存(并不是一个好方案,最终ban掉了),在生成缓存处理数据中发现了一些优化点,可以提高速度,在此记录一下,首先可以了解一下如何利用工具找出代码中一些代码块的执行速度。
二、pprof
2.1 简介
pprof 是用于可视化和分析性能分析数据的工具,这里主要用来定位性能问题
主要有以下数据:
CPU Profiling:CPU 分析,按照一定的频率采集所监听的应用程序 CPU(含寄存器)的使用情况,可确定应用程序在主动消耗 CPU 周期时花费时间的位置Memory Profiling:内存分析,在应用程序进行堆分配时记录堆栈跟踪,用于监视当前和历史内存使用情况,以及检查内存泄漏Block Profiling:阻塞分析,记录 goroutine 阻塞等待同步(包括定时器通道)的位置Mutex Profiling:互斥锁分析,报告互斥锁的竞争情况
这里我们主要用到第一点
2.2 结果分析
这里使用的是web应用,可以使用 net/http/pprof库,它能够在提供 HTTP 服务进行分析
1 | go tool pprof "http://127.0.0.1:8090/debug/pprof/profile" |
输入命令后并调用接口,30s后会暂停,然后输入web命令出现下面的页面
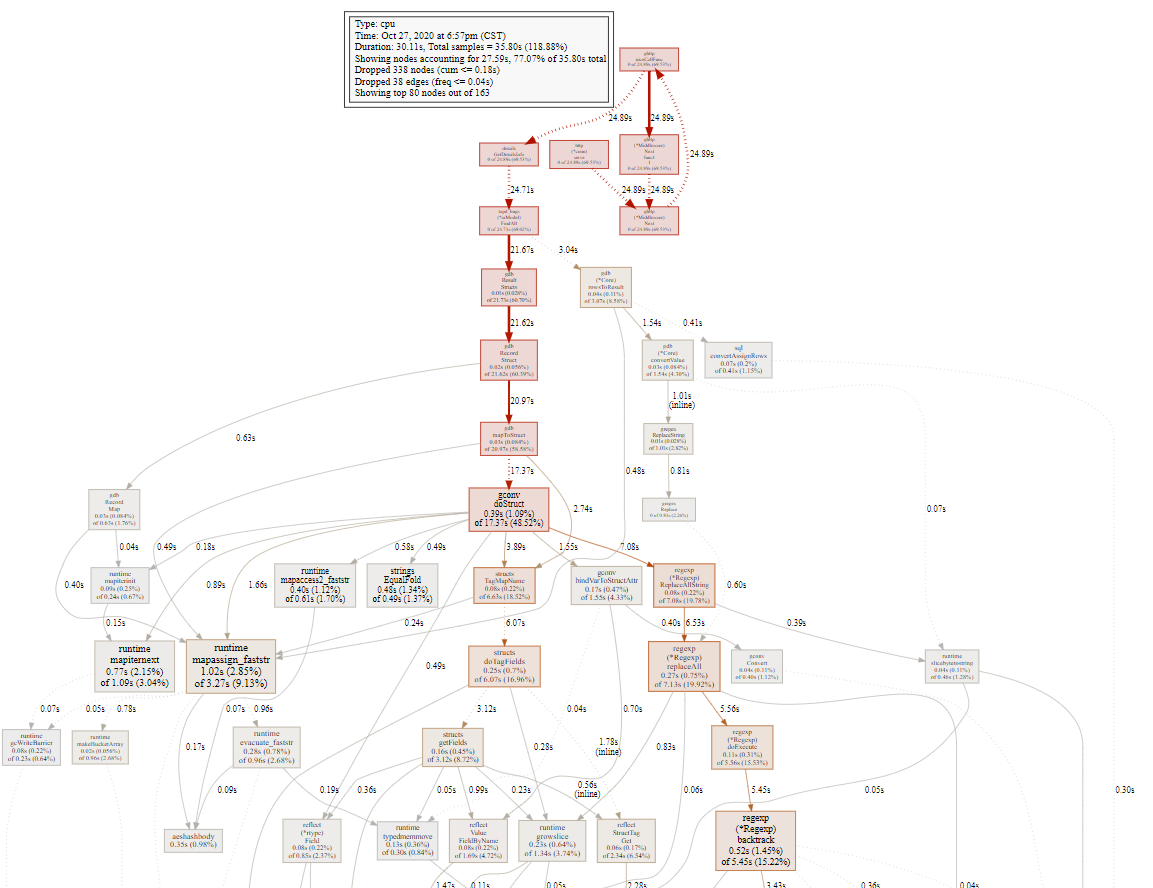
这个是pprof的Graph视图,记录了调用方法所花的时间和调用链,我们一般会关注红色颜色比较深的那一块,然后找到自己写的方法
 .png)
.png)
2.3 找到关键部分
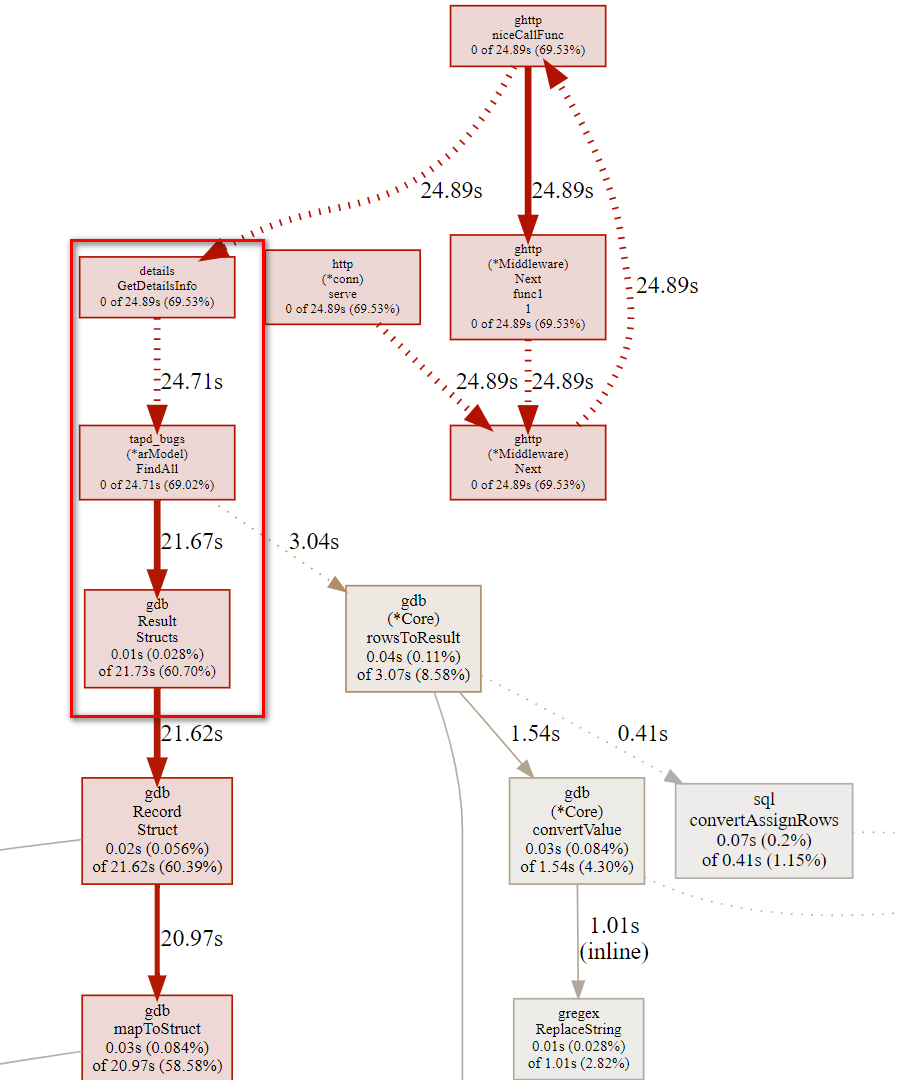
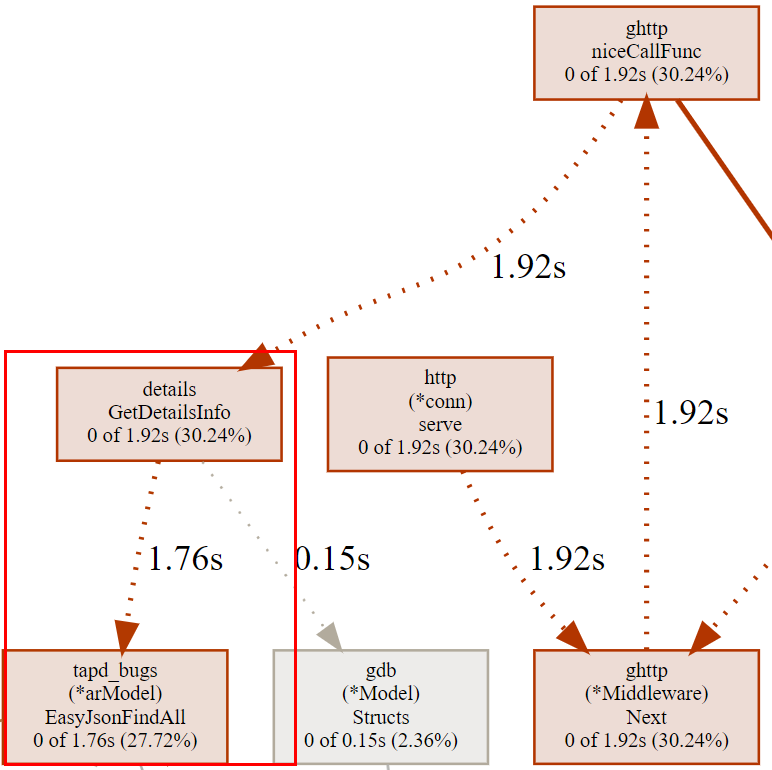
从顶端开始找到第一个自己的业务方法,这里为GetDetailsInfo
然后我们可以输入命令list GetDetailsInfo 获得详细信息
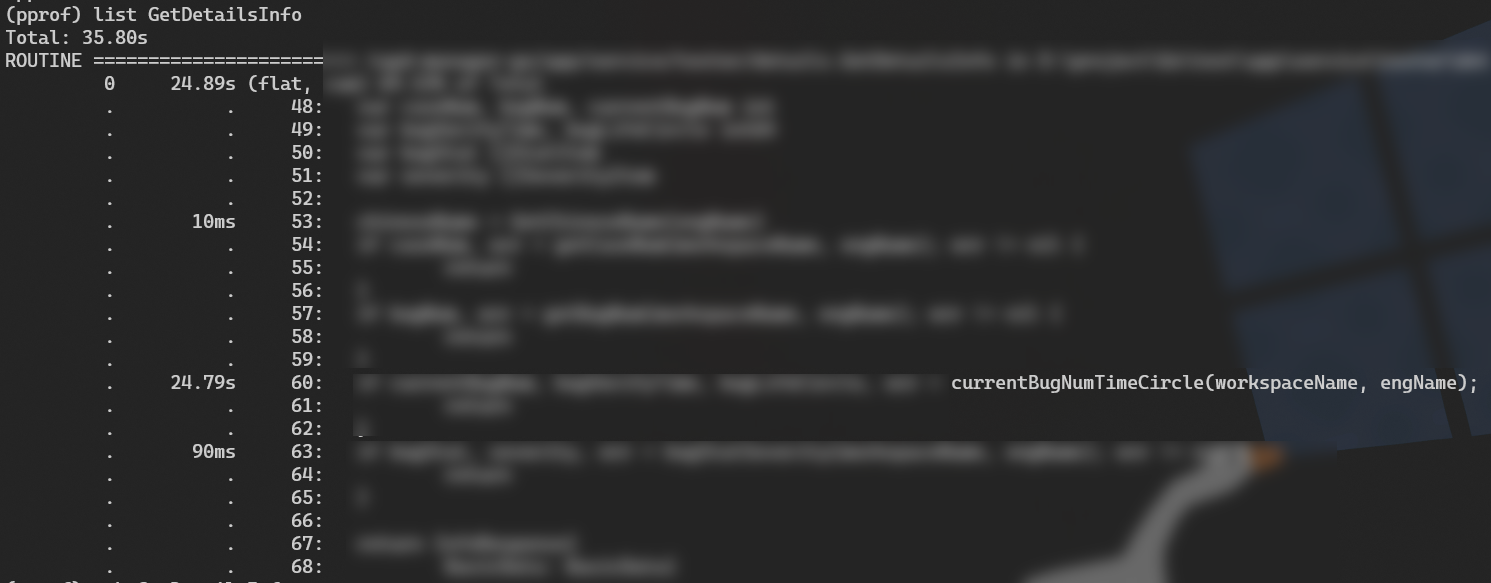
这里定位到60行花销的时间最多,但是这个还是个方法,我们可以回到终端输入web GetDetailsInfo 命令显示详细一点信息。
![]项目Golang优化点/Untitled%203.png)
定位128行,这里是使用的GoFrame框架带的orm查询语句,再往下的代码则是框架的源码,至此,利用pprof找问题可以告一段落
三、优化点
3.1 反序列化
3.1.1 找出关键点
对同一接口调用三次,然后利用pprof找出缺陷点
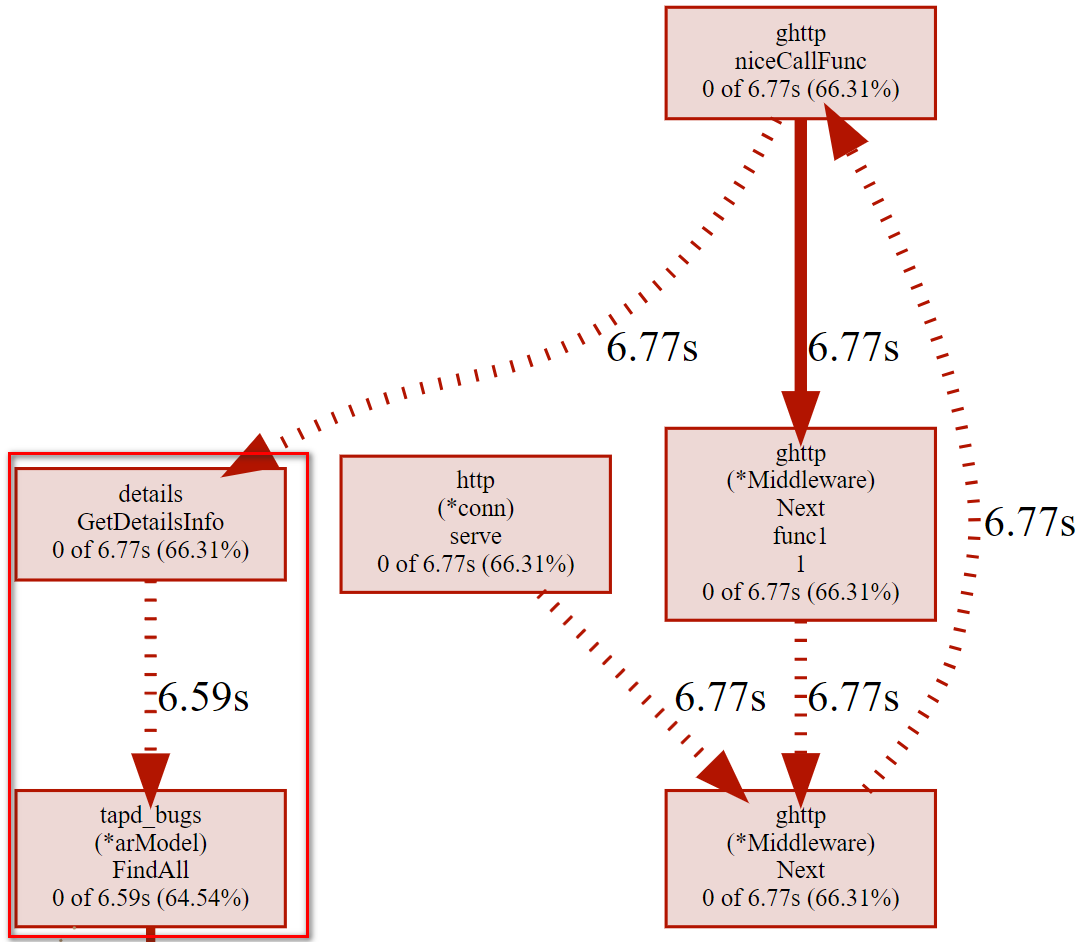
这里面可以看到,绝大部分时间都花在了FindAll 方法上面了,查看这一部分源码
1 | tapd_bugs.FindAll(tapd_bugs.Columns.WorkspaceName, workspaceName) |
这一部分代码的作用是从数据库拿出数据并反序列化到结构体上面,SQL查询语句相当于
1 | SELECT * |
首先我们得查看从数据库拿出数据大概需要多久
从程序打印出来的log日志中看到,从数据库拿数据花费的时间不到10ms(大概8w数据)
![]项目Golang优化点/Untitled%205.png)
那么问题可能出在了反序列化上面了,这里的反序列化意思大概是
拿到的数据格式大概是这样,是一个json数组(这里实际是[]byte数组,只不过ide显示友好化了)
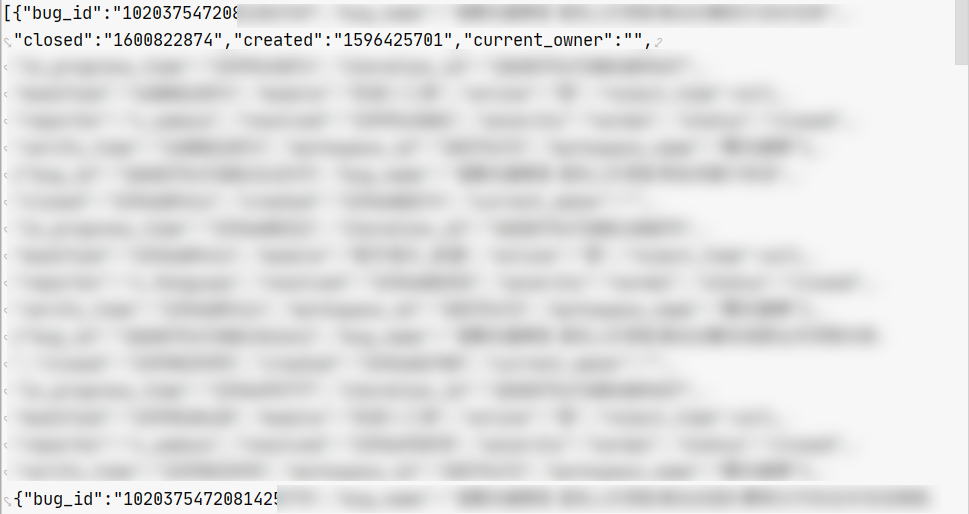
经过我们反序列化后,就可以将这些值放到结构体中,就相当于确定化了
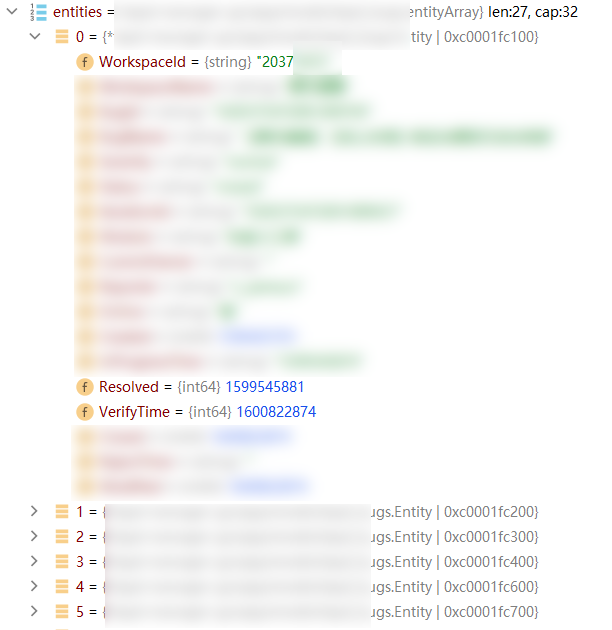
我们查看下这部分源码
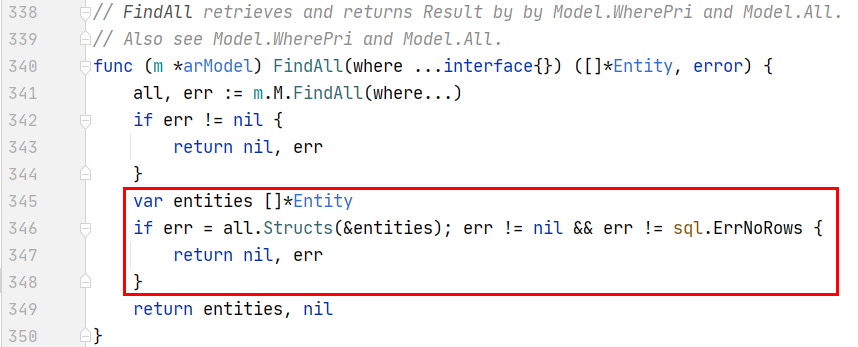
这里可以明显看出代码346行是将查询的数据all反序列化到entities ,那么问题就应该出现在红框那一块,点进去查看源码的话
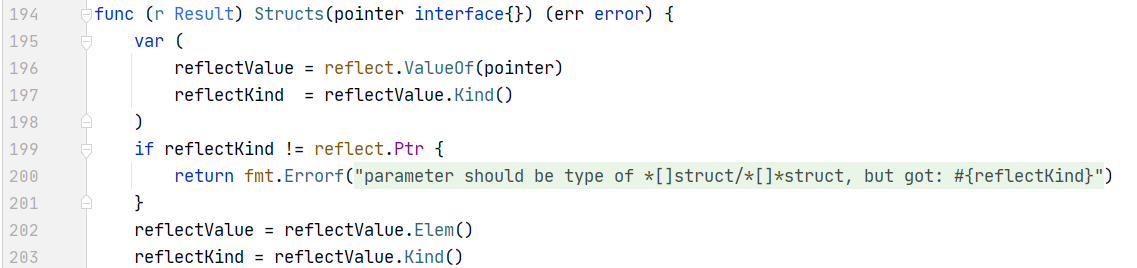
我们可以看到很多关于reflect包的函数,可以很明显看出这里使用了反射的方式反序列化
3.1.2 反序列化处理过程
假设我们有如下JSON:
1 | [ |
和如下结构体:
1 | type User struct { |
那么使用该方法反序列化一般的过程是怎么样的呢,怎么能够把JSON里面的数据映射到结构体里面呢?
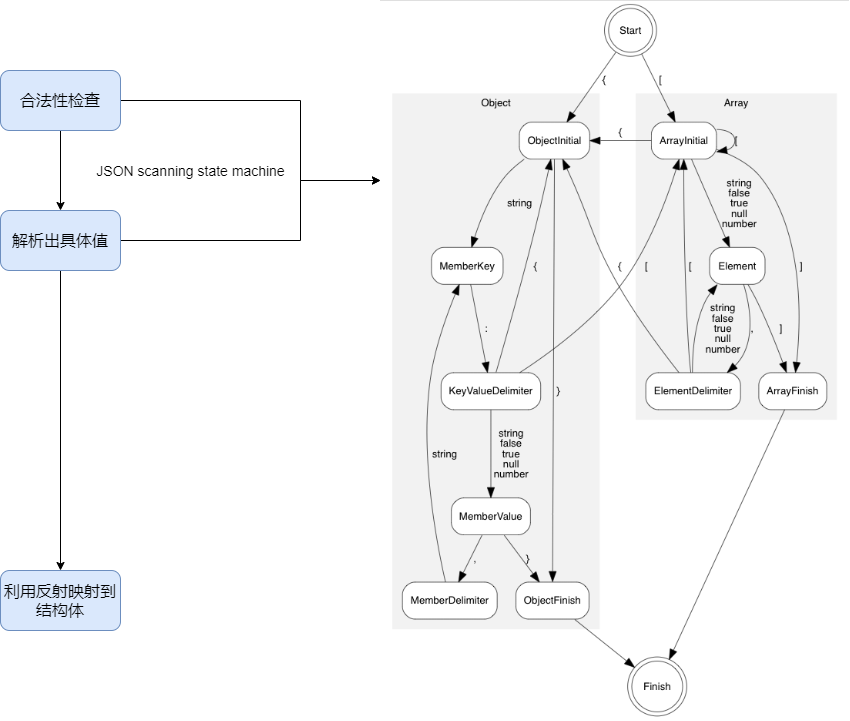
- 首先会利用JSON扫描状态机对输入的JSON byte数组进行合法性检查,以保证后面操作JSON的正确性
- 接着会利用状态机对JSON进行解析,提取出key,value等信息
- 最后利用反射,将这些信息映射到结构体中
利用反射我们可以在运行时对结构体动态赋值,对于一般结构体赋值我们可以这样显式赋值:
1 | User{"张三", 21} |
但是这样就太限制了。因为对于一般的情况,我们是不知道传入的结构体和JSON的结构是怎么样的,所以我们就需要一种技术能够让我们在运行时动态获取到结构体相关的信息(比如类型和值),并且有一些方法能够操纵这些数据,比如赋值,这样的话我们就能够动态去处理这些数据了,反射能够提供方法支持,所以就是我们要用反射的原因。
3.1.3 反射
- 通过
reflect.TypeOf(i interface{})我们能拿到变量的类型 - 通过
reflect.ValueOf(i interface{})我们能拿到变量的值
如果我们知道了一个变量的类型和值,那么就意味着知道了这个变量的全部信息。
有了变量的类型之后,我们可以通过 Method 方法获得类型实现的方法,通过 Field 获取类型包含的全部字段。对于不同的类型,我们也可以调用不同的方法获取相关信息:
- 结构体:获取字段的数量并通过下标和字段名获取字段
StructField; - 哈希表:获取哈希表的
Key类型; - 函数或方法:获取入参和返回值的类型;
- …
接着我们可以利用reflect.Value.Set 方法更新反射对象,所以我们可以看到下面的这个代码,传入一个空的entities数组,然后就可以得到有具体值的entities数组
反射的原理可以大概理解为:
因为传入的数据都是interface{}类型,其在内部存储了分配给该变量的具体值(the concrete value assigned to the variable)以及该值的类型描述符(value's type descriptor)
在build时,Go linker会将有关应用程序使用的所有类型的信息嵌入到可执行文件中
转换【编译时已知的类型】到【interface{}】的过程中,GO编译器会将类型描述符指向具体的类型描述符,这是编译时已知的,所以通过这两个就能拿到相关的信息。
3.1.4 反射缺点
对于本项目来讲,缺点就是慢,特别是数据量多需要循环调用反射的时候,主要的原因在于:
- 涉及到内存分配以及后续的GC
- 每次执行时都需要验证执行的每个步骤
- 查找类型信息时
I/O速度慢 - 等等
3.1.5 解决方法
既然反序列化过程比较慢,那么我们可以使用第三方JSON库去提高效率。仅需要修改下源码,将structs部分去掉,改为调用第三方JSON库的解析方式。
对于序列化库的实现来讲,如果在运行时通过反射的方式进行序列化和反序列化,性能不会太好,所以高性能的序列化库很多都是通过代码生成在编译的时候提供序列化和反序列化的方法。因为在编译的时候已经知道每个字段的类型,所以无需元数据,可以聪明的对字节按照流的方式顺序处理以及作更多的优化。
效率对比
3.1.6 方案缺点
- 因为代码是提前生成的,所以灵活性不强
- 适用于大量数据序列化场景,如果数据量不强,效果不明显,反而增加成本
- 需要明确反序列化后的结构
3.2 Redis mset key
3.2.1 找出关键点
项目需要一下设置很多缓存,这个也是个优化点,因为pprof不能捕获到for循环中Redis set key的所花费的时间,所以我们只能手动打点
1 | start := time.Now() |
这里数据大概有1k条,每条数据序列后长度不到20000
跑了一下上面的打点,需要花费8.8595475s
这里瓶颈主要在于循环调用,多次调用会增加开销:
因为Redis本身是基于request/response模式,每一个命令都需要等待上一个命令响应后进行处理,中间需要经过RTT(Round Time Trip,往返延时,表示发送端从发送数据开始,到发送端收到来自接收端的确认,所需要的时间。),并且需要频繁调用系统I/O
单次setx的操作所花费的时间为22.9419ms 压缩字符串后能减少到17.9522ms 但是整体调用起来差别不大
1 | g.Redis().Do("SETEX", key, expiredTime, |
3.2.2 mset
对于这种需求,一个更好的方法使用MSET命令,可以一次性设置多个key value
1 | MSET k1 "good" k2 "bye" |
这个命令是原子的,要不全部完成要么完全不完成,不会看到一部分值被更新,而其他值未更新这种情况。该命令执行后会返回”ok”字符串。
从Redis官方文档来看,该命令每次都是会返回成功,不会失败
Return value
Simple string reply: always OK since MSET can’t fail.
这里的意思是不会在MSET 阶段返回错误,有错误的话Redis会提前返回:
在处理命令之前会检查内存容量,如果内存容量不够,无论命令的实际响应如何,都会返回错误响应
效率对比:
8.8595475s → 1.3812954s
3.2.3 方案缺点
使用 MSET 不能设置过期时间,我们可以使用Lua脚本处理,这里是一个批量设置xx:xx:前缀的key过期时间脚本的示例。可直接在Redis-cli中执行。
1 | eval |
可以使用 eval命令执行Lua脚本
EVAL script numkeys key [key ...] arg [arg ...]
- 上面最后0代表0个key
redis.call执行Redis 命令ipairs遍历集合
3.3 其他优化
其他优化点都是很常见的,比如:
- 加索引
- 多线程优化
- 避免多次调SQL,一次性查出来映射到map
- 等等
这里就不赘述。