CMU445-Project1-ExtendibleHashTable总结
前提:搞懂https://www.geeksforgeeks.org/extendible-hashing-dynamic-approach-to-dbms/
Why
https://15445.courses.cs.cmu.edu/fall2022/project1/
待补充,可看原论文
设计要点:
- Page Fault
- Access Memory/Disk
- Dynamic File Organization
- Balance Radix Search Tree
- Static & Dynamic Hash
Concepts
- $h$: fixed hash function
- $K$: is a key
- $K’$: $h(K)$, also $pseudokey$.
- We choose pseudokeys to be of fixed length, such as 32 bits.
- The pseudokeys are of fixed length, the keys need not be.
- $I(K)$: is associated information: either the record associated with $K$, or a pointer to the record.
Struct
基本结构如下:
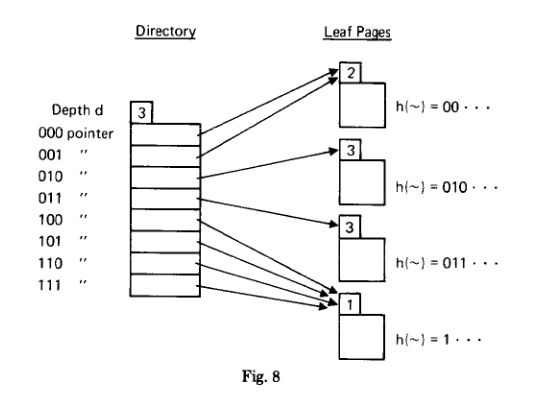
- Two levels: $directory$ and $leaves$
- The leaves contain pairs$(K, I(K))$
- The directory contains pointers to leaf pages
- Depth d: the depth $d$ of the directory.
Directory pointers:
- First, There is a pointer to a leaf that stores all keys $K$ for which the pseudokey $K’ = h(K)$ starts with $d$ consecutive zeros.
directory第一个指针指向的leaf中所有的$K$有下面的特征:$K’$前$d$位都是0 - 第二个指针指向的leaf中所有的$k’$前$d$位是
0...01,第三个是0...010,后面以此类推。 - 所以directory总共$2^d$个pointer
- First, There is a pointer to a leaf that stores all keys $K$ for which the pseudokey $K’ = h(K)$ starts with $d$ consecutive zeros.
Find $K$:
- 计算出$K’$, 找出其前$d$位.
- 找到这$d$位对应的是directory哪个pointer
- 然后可以找到leaf,在leaf中遍历pairs
Leaf header:
- Each leaf page has a header that contains a local depth $d’$ for the leaf page.
- 举例directory中
000pointer指向的leaf: Local depth 2 means that not only does this leaf page contain all keys whose pseudokey begins with 000, but even more, it containsall keys whose pseudokey begins with the 2 bits 00. Thus the 001 pointer also points to this leaf page. - $d’ <= d$
Insert
这里以lab的要求为准:
- 在编程中计算后$d$位比较方便,和上面看前$d$位有所区别,但是原理相同
- leaf在lab中称为Bucket
Structure
lab中extendible hash table结构如下:
1 | int global_depth_; // The global depth of the directory |
Bucket结构:
1 | template <typename K, typename V> |
所以dir_里面保存了directory pointer,bucket_size_代表每个bucket最大容量是多少,Bucket中的list_保存了上述讲的pairs
Init
初始情况下global_depth为0,总共有$2^0=1$个bucket,所以num_buckets=1,bucket_size每个用例都是不一样的,每个bucket里面都还是空的。
Indexof
For the given key, return the entry index in the directory where the key hashes to.
1 | template <typename K, typename V> |
- mask
- 对1左移global_depth位,即在1的二进制后面加global_depth个0,然后-1
- 比如
(1<<4)-1: 1<<4 可以写成二进制形式 10000,然后再减去 1,为 1111。 - 所以这mask为global_depth个1
std::hash<K>()(key) & mask- 这里取&为的是将index控制在一定数量的位数上,该位数由globaldepth变量确定,也就是index不能超过$2^d$,比如global_depth=2,有4个bucket,index最大为3,3的二进制是11,正好是global_depth个1
- 这里意思也就是看后global depth位
Case1
1 | auto table = std::make_unique<ExtendibleHashTable<int, std::string>>(2); |
这里bucket_size为2
1 | table->Insert(1, "a"); |
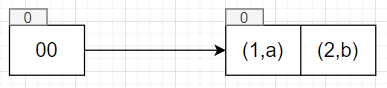
1 | table->Insert(3, "c"); |
这时候bucket已经满了,正常情况下处理bucket满的策略有两个,double directory和split bucket only。
采用哪个策略需要看global depth和已满的bucket的local depth:
Bucket Full
- 如果global depth == local depth,需要double directory。为什么呢,这是由两个depth代表的意思决定,两个相等,代表该bucket只有一个directory pointer指向,没有多余的pointer来指向了,只能是增加pointer。至于为什么是double呢,我想这里可能和二进制方便运算有关系吧,也许这样处理起来比较规整?
- 因为local depth不会大于global depth(两个相等时double directory,global depth都会+1),所以还有一种情况是global depth > local depth,global depth代表了找到key需要看后几位bit,local depth代表了该bucket里面的key后local depth位都是相同的,当global depth > local depth时,因为看的位数的差异,自然会有多个directory pointer指向这个bucket,那么这时候只需要split bucket就好了,有多余的pointer能指向新的bucket。
Double Directory
这里global depth和local depth相等,所以执行double directory逻辑,假设原先满的bucket是bucket j:
global depth = global depth+1
directory翻倍,多出来的pointer按顺序指向原pointer
- 比如原先directory size为4,double后变成8,那么多出来的
dir_[4]指向dir_[0],dir_[5]指向dir_[1],6指向2,7指向3。 - 假设这里每个directory pointer只有一个对应的bucket,那么这里的操作就是每个bucket多了个pointer指向。
- 这里其实也好理解,比如原先pointer是
010,double directory后,无非就是多了一位二进制,对应到directory要么是0010,要么是1010,因为local depth目前还没有到+1的地步,所以这两个先指向同一个bucket也可以。
- 比如原先directory size为4,double后变成8,那么多出来的
创建一个新的bucket z,设置bucket j、bucket z的local depth=global depth
对bucket j的里面所有的key执行rehash操作,判断该key是留在bucket j还是移动到bucket z。
重试插入操作,一般情况下会插入成功,某些情况下会插入失败,比如rehash时候所有的key还是在bucket j,这时候就需要重新执行插入逻辑,重新判断是需要 double directory还是split bucket。
一般情况下如果选择的hash函数合适的话,那么一次split即可。极端情况下会退化生成静态hash那样解决冲突,同时应该设定最大的directory depth)。
Rehash
rehash过程其实就是看bucket j里面所有的key是放在bucket j还是bucket z。在double directory的情况下,多看了一位,所以是新增二进制位(也可以说是从低到高第global depth/local depth位,此时global depth=local depth)为1的话就放在bucket z。
这里实现的方式有两种,一种是直接调用erase将key从bucket中移除,另外一种是使用先将key放到hashmap<directory index, value list>,然后根据hashmap的key重新将value分配到bucket,因为每次只涉及到两个bucket,所以hashmap的length不大于2,理想情况是2,极端情况是1,也就是上面讲的所有的key都还在bucket j。
因为directory中可能有多个index指向bucket j,所以这里还得更新下别的index指向。这里处理的逻辑是,遍历所有的index,如果这个index之前指向的是bucket j,但是对应的新增的二进制位是1的话,就需要将这个index指向bucket z。
Insert
回到table->Insert(3, "c");,此时执行double directory和Rehash逻辑
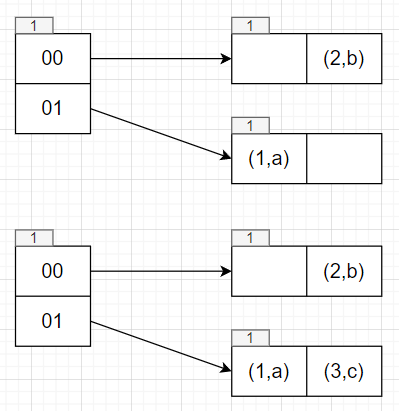
1 | table->Insert(4, "d"); |
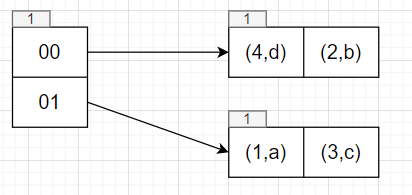
1 | table->Insert(5, "e"); |
需要插入index为01的位置,执行double directory逻辑
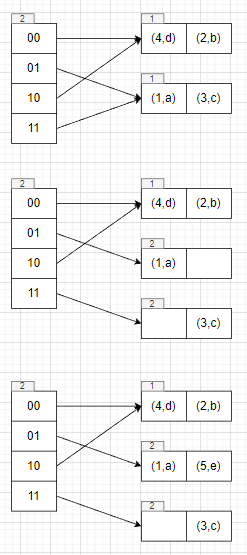
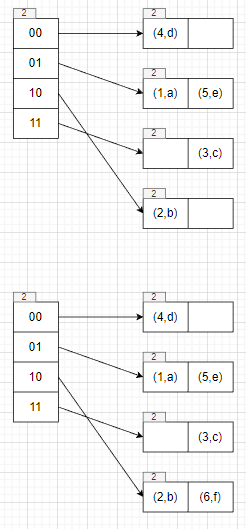
1 | table->Insert(6, "f"); |
此时需要插入index=10对应的bucket,该bucket已经满了,因为global depth > local depth,所以执行split bucket逻辑即可。
Split Bucket
- 创建一个新的bucket z,设置bucket j、bucket z的local depth= local depth + 1
- 对bucket j的里面所有的key执行rehash操作,判断该key是留在bucket j还是移动到bucket z。
- 这里和double directory的逻辑有点区别,但是大体相似。这里看的是从低到高第local depth位是否为1,因为只变了local depth。同样也得处理多个index指向同一个bucket的情况。
- 重试插入的操作和double directory操作一样
Insert
1 | table->Insert(6, "f"); |
1 | table->Insert(7, "g"); |
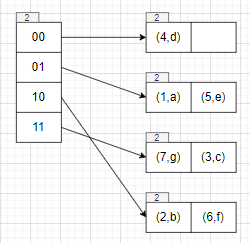
1 | table->Insert(8, "h"); |
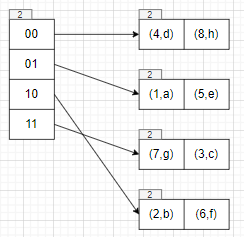
1 | table->Insert(9, "i"); |
1 | dir_ global depth: 3 |
Case2
1 | auto table = std::make_unique<ExtendibleHashTable<int, int>>(2); |
1 | [Init] bucket_size:2 |
Case3
1 | TEST(ExtendibleHashTableTest, GetNumBuckets2) { |
1 | [Init] bucket_size:4 |
Case4
1 | auto table = std::make_unique<ExtendibleHashTable<int, int>>(4); |
1 | [Init] bucket_size:4 |